
Introduction
The human civilization started to curate, interpret and summarize data very early on, in order to bring out the value and insights. Patañjali (prior to 400 CE), compiled the Yoga Sūtras in 196 sutras, in an attempt to simplify the yogic science. Another example of applied data science is classification, where the Greek philosopher, Aristotle (384—322 B.C.E.) was the first to classify areas of human knowledge into the distinct disciplines of mathematics, biology, and ethics.
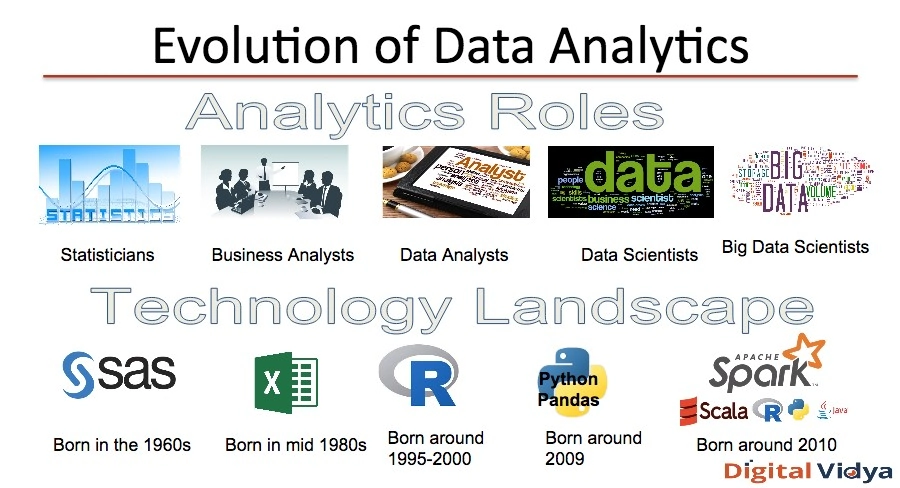
Coming forward to the 20th century, in the early 1900s, the Statistician, Gosset, working with a brewery, applied his statistical knowledge – both in the brewery and on the farm – to the selection of the best yielding varieties of barley. The statistical modeling largely stayed with the mathematicians and statisticians into the 21st century, until very recently, where now the software tools like Excel, SAS and programming languages like R and Python enable the practitioners from myriad fields, to apply the statistical algorithms using the readily available methods and libraries.
The Evolution of the Data Landscape & the Technologies that Rule
The Birth of SAS
The digital era of data science, was launched in the mid-1900s, when North Carolina State University’s (NCSU) agricultural department, began the project, which became the foundation of the Statistical Analysis System (SAS). In the early 1970s, the software was primarily leased to other agricultural departments in order to analyze the effect soil, weather and seed varieties had on crop yields. SAS software became very popular with the Banking, Finance, Insurance, Pharma industries and has continues its dominance in the new age of data. It has evolved to support the requirements of text analytics, natural language processing, high power analytics and visualizations. This continues to rule the statistical modelling of large businesses.
The R Programming Language by Statisticians
The most popular programming language for data analysts was not born from the software research labs, but rather from the need of Statistic Professors, to have a technology that suited for their statistics students. Ross Ihaka and Robert Gentleman, gave lectures on statistics in the University of Auckland. At first, developing the language was a mere hobby for the professors, considering that none of them had any deep computer science training. But starting in 1991, both Ihaka and Gentleman started working full time in developing their new software. This came to became one of the most widely used programming languages by statisticians and data analyst professionals due its open source contributed rich set of libraries, and continues to dominate the data science industry.
Microsoft Excel became the Jack of all Trades, Literally
In the last 3 decades, this tool has been used in pretty much at all places – homes, personal, small and medium companies, large organizations and industries, and in all functions and roles. O’Rielly conducted a survey in Europe in 2016, and published its report in 2017. The survey asked for the tools used by the Data Analysts in their roles, and 70% of the respondents listed Excel. This is a pretty large endorsement for Excel based analysts in 2017, and that building advanced skills in Excel, and combining it with the Data Analysis add-in pack, can position professionals to do their jobs significantly better, and make informed decisions based on data. The functions of HR, recruiter, marketers, sales, supply-chain specialist, procurement, operations, delivery, to name a sub-set who handle data and can very well leverage the power of data using a tool that makes analytics accessible to them.
Python Pandas and Scikit-Learn
As the Data Analytics shifted into the mainstream businesses, the field started to be infiltrated by the computer science academia and the working professionals. The developers at a financial management firm, AQR, started to develop a tool to perform analysis on the financial data, which was then open-sourced giving a strong foundation to the data analytics libraries for one of the most popular and general purpose programming languages. Python got consolidated for the machine learning libraries, with the contribution of Scikit-Learn, that was initially developed by David Cournapeau as a Google summer project. The unique capability that Python brings of being a general purpose widely uses programming language, lending itself to a powerful data analytics and machine learning capability, means that the software professionals turned data scientists have taken towards a large adoption in the area of data science.
The Foundation of Big Data Technologies
The growth of data in the famous 5 Vs – Volume (driven by the interconnected world), Velocity (generation per second), Variety (from traditional structured transactional data to data in forms of text, pictures, visuals, videos), Veracity (truthfulness of the data), leading to the most important outcome drive V – Value. The Hadoop based framework has increasingly becoming the choice of the organization needing to deal with 2 or more of the Vs with an array of tools enabling data engineering of the Big Data.
Apache Spark is becoming the prominent cluster-computing processing framework for its high performing streaming and machine learning library. The Spark Core exposes its distributed task dispatching, scheduling, and basic I/O functionalities, through an application programming interface supported for a large array of languages, Java, Python, Scala, and R.
Summarizing
In summary, it is rather an ambiguous question to choose the technology to build our data scientist careers, without a context. The decision needs to be based on the background, industry domain and prospects. The technologies will continue to evolve, as they must to meet the demands that the growth and complexity of data that humans are generating. The important point to note is that all listed technologies are being widely used in the industry, and have a huge potential.
One extremely simplified way to help think is, Python for programmers, R for Statisticians & Mathematicians and other software folks, who want to pursue a programming based tool to perform data analysis. SAS for folks who are in the domain of pharma, healthcare, insurance, finance. All functional roles under the sun that deal with data, learning advanced techniques of excel is a clear virtue.
Remember, simplification is not always accurate, but helpful.
The Evolution of the Analysts Role in Data Science
The evolution of the data in businesses has meant that there have been a variety of roles; functional and technology-based; that organizations need in order to harness the data for their businesses.
The organizations needed domain experts who can understand their business, involved in identifying problems, needs, and opportunities for improvement at all levels of an organization. This led to the positions of Business Analyst whose role is business and function-centric.
With data becoming the new natural resource that needs to be mined, the evolution of the analyst roles created a new floodgates to a new set of skills called the data analysts. The key difference to note is that this role data-driven.
The journey to becoming a Data Scientist – This is where the marriage of all the above roles becomes a possibility. In 2010, Drew Conway, a social- behavioral problem solver, curated a venn diagram that has become one of the most used visual to demonstrate the competencies that different roles bring together to make a competent Data Scientist.
This diagram was an outcome from O’Reilly hosted discussion on skills needed for data career, and many years later, with the data roles becoming a lot more common across different organizations, the competencies can provide an excellent reference skill-set. Let me summarize them:
a.) The data hacker – is the person who is skilled at gathering, collecting, cleaning data, applying and building algorithms.
b.) The statistician – even through the data-centric roles are no more confined to the fields of statisticians, the data analyst is expected to acquire a reasonable to strong knowledge of the statistical models, and application of it, be able to train the machine learning models and improve them.
c.) The domain expert – the skill that comes from deep insight of the industry, such that the domain data can be curated and then the leading questions should help build the questions that enable to discover next actions in the business.
Conclusion
Data is the new ‘Gold or Oil’, and it is imperative that all the different business functions are able to access and discover data, understand and interpret it, apply statistical modeling and fine tune the method to gain the right level of insight and enable a truth based decision making. The industry is ready, and with acquiring the right level of skills, in statistics and armed with the right programming tool or advanced spreadsheet and visualization, one can mine the gold and make a fine outcome of it, impacting their domain and industry.


















Am an MBA finance graduate 2015 output. Currently working in operations, I do not have any background of technology or about Data scientist or Data analyst. Can I take this course or how it will help me to grow in future??
Hi Ajay, Thank You for trusting us with your query.
Data is a very important aspect of “Data Science” and it is the fact that the various functional areas who own the real data, in roles of operations/sales/marketing, must have the power of data analytics.
We have created a curriculum to specifically fulfill this need, where people like yourself would leverage the power of Microsoft Excel, and Business Intelligence tool, PowerBI. This is one of our most popular courses with people from different industries, especially in finance, operations, sales and marketing.
I would like to draw your attention to the 2017 European Data Science Salary Survey, where 70% respondents have chosen Excel as their tool of choice for solving data analytics business problems.
If you would like to go deeper using a programming language, then Python is looking to be the future of Data Science.
Hope this gives you some clarity.
Firstly thanks to your team for the good information and insights provided. Can this course address the following challenge : Transition of a person having 20 years experience in E R P software in implementation and support roles (completely non-programming but exposure to business basics of various verticals) in to a mid-senior / senior level Analytic s role. Please throw light on the functional / non-programming aspects rather than big-data in your answer. Thank you very much.
Hi Kalyan, We have been talking to the folks in analytical services industry. The analytics projects, like other implementations (including ERP), definitely have the business and functional roles.
The companies when looking for talent in the area look for people look who are skilled in Statistics, Machine learning models, and know some programming, so that they can be effective while working with the clients in understanding their business drivers and address them through data.
The focus for our course is to help people become Data Scientists by learning the programming techniques. Considering what profiles an individual wants to pursue will need to then sharpen skills accordingly, the hand-on data scientists/programmers will need to practice solving data problems and doing considerable machine learning. The senior business and functional roles, will need to focus on Statistics and understanding Machine Learning models and its applications. One may still have to undergo analytical and coding tests to apply for the senior roles, this will vary company to company.
Hope I answer your question.
As an actuary, what aspect of data analytics should I consider learning?
Hello Ezekiel,
You need the same basic foundation of Statistics and a software tool or a programming language to get into data analytics and Machine Learning for the field of actuary. You could go with Data Analytics using Python if you are confident by getting a heads up in python programming.
The second option is learning the SAS software, especially if intend to work with the big organizations. Read this paper from SAS:
https://www.sas.com/en_au/whitepapers/actuarial-challenges-whats-analytics-got-to-do-with-it-104308.html
Some more discussion here:
http://www.actuarialpost.co.uk/article/data-scientist-vs-actuary-9677.htm
Hi Shweta,
As we know data analysis is an important factor for each and every profession, i have following queries in this regard
1. How it would benefit a Chartered Accountant
2. Scope if i want to chose as career option and correspondong opportunities in market
3. Which technology is preferable for an chartered accountant like excel, sas or phython etc. Bcos in detail it goes into technical form and need that sets of skill which a chartered accountant doesnt have like knowledge of programming languages
Hi Sharad,
I am sure that as CAs, you would find that data analytics is extremely useful in performing many of the crucial tasks like auditing. However, I don’t have access to reports or articles from CAs who do this, but it does appear that it is not a broadly available skill and therefore the value is still to be uncovered.
I was hoping to find some detailed answers in Quora, however this needs inputs from the community:
https://www.quora.com/What-is-the-scope-for-a-chartered-accountant-in-the-field-of-data-analytics-in-India
Now coming to the possibilities. Once you know how to work with data in terms of slicing/dicing and performing some transformations on it, to Statistics, Visualization, you will be able to bring a lot more value from the data that you collect.
One needs to build skills, and one of the most powerful tools are Microsoft Excel and PowerBI alongwith the foundation of Statistics.
If you want to then go deeper into building the models, one will need to learn programming or build a team.
Hii ,
I am BCA/MBA in Marketing,currently working in Admin department having 4 years of experience. I do not have any background of technology or about Data scientist or Data analyst. Can I take this course or how it will help me to grow in future??
I am not good in programming.
Hi Priyanka, I am slightly confused, as you say you have done BCA, that is Bachelor in Computer Applications, however you also say that you do not have background in technology. What was your course about?
Considering that you call yourself non-tech, I would recommend that you start with ‘Analytic Techniques using Excel and PowerBI’. This will definitely help you become advanced Excel user, and you can do pretty good insights, and power with Statistics and a Visualization tool of PowerBI, you can look for Business Intelligence (BI) roles.
hai swetha.. i am doing my M.Sc Computer Science course..Now last semester going on..This semester i doing my project in Data analytics. But i dont know what is data analytics ..My guide told us to me to learn Python language thoroughly … so how it will be useful in my education?
Hi Revathy,
You say that you have a project to do, and you don’t know the subject. I hope your course covers some introductory Data Science or it may not. Academia is often slow to catch on the most relevant skills required in the industry.
I would agree with your guide, and definitely encourage you to learn Python as a programming tool for Data Science. We have many students like yourself successfully learning with us. Why don’t you register for the Orientation so that you get a head start and then we will help you register yourself to do the course.
Regards and Cheers!!
Hi Shweta,
Am IT Infrastructure and Service Delivery ( user support ) guy having some 14 + exp , but feeling need to have changed or evolved profile further considering the disruptions in the tech market. Can you advise some course suitable to my stuff.
Hi Rajesh,
I would solicit a discussion with you before we get into the skill building part. The technology space can be very vast, and to understand your interests and more about current skill set, it will judicious to first brainstorm a little bit. Please email on shweta.gupta@digitalvidya.com with your contact and suitable time for us to call you.
Cheers,
Shweta
Hi Shweta,
I am a graduate. I completed my graduation 10 years back and working in an MNC as Sales and Marketing associate. I would like to enhance my career by doing data analytics. However, I am not sure where to start from and what’s best for me.
Hello,
I have done my bsc chemistry and currently working in MNC company, as a back end executive. I want to take this course to make my future in data science.
Do you have training center at Gandhinagar gujarat.
Regards
Karan
Dear Karan,
We have all our classes conducted online. Do talk to us for further discussion.
Cheers,
Shweta
Hi,
I am graduated in BBA, working as a market research executive so, I want to know would I am able to persue data analytics course ? If no, please help me with suitable course.
Regards
Taruna Chauhan
Thanks for showing faith in our advice.
Firstly, it is good that you have done a course in Business and then taken up Market Research. That is a perfect place to start.
Now coming to your question. Yes, you may take up a Data Analytics Course as most of the decision making in the current day business environment is based on the analysis of Data. Now, Data that is unsolved doesn’t solve many business puzzles, and Analytics plays a major role in making large unstructured data informative. That’s where Data Analytics comes to rescue.
Data Analytics is a budding industry and with an increase in data, it’s only growing. Another good thing is that Data Analytics doesn’t need any coding experience. In our estimation, Data Analytics is a great course for you. We would strongly recommend it to you.
Thanks.