
Decision Tree Learning – Introduction
A tree is utilitarian in real life, and it turns out it has influenced a broad area of Machine Learning. In Decision Tree Machine Learning, a decision tree can be used to represent decision and decision making, visually and explicitly.
According to Mckinsey Global Institute, 20% of C-level executives report that they are using machine learning (or AI) as a core part of their business.
Though it is a frequently used tool in Data mining for obtaining a strategy to reach a particular goal, it is also widely used in machine learning these days which will be our main focus of this article.
“Machine learning will automate jobs that most people thought could only be done by people.” – Dave Waters
Firstly, in the process of Decision Tree Learning, we are going to learn how to represent and create decision trees.
Followed by that, we will take a look at the background process or decision tree learning including some mathematical aspects of the algorithm and decision tree machine learning example.
Before ending this article, we shall discuss the advantages, disadvantages of the algorithm & the process of learning decision trees in artificial intelligence. Let’s get started with the representation.
Decision Tree Learning – Representation
Just like before learning any advanced topic you first must completely understand the base theory, before learning decision trees in artificial intelligence you must know how basic decision trees work in data mining as we discussed.

For all those folks digging around machine learning must know about the great Titanic dataset. For those who don’t, it is a large dataset for predicting whether a passenger will survive or not.
The model below uses 3 features from the dataset namely gender, age, and sibsp, which is a number of spouse or child along.
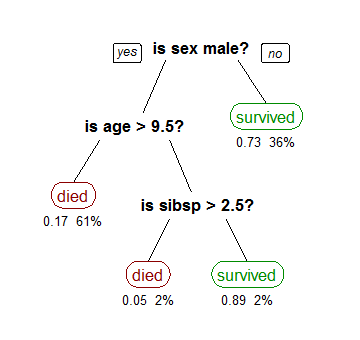
A decision tree is always drawn upside down, meaning the root at the top. As you can see in the image, the bold text represents the condition and is referred to as an internal node.
Based on the internal node the tree splits into branches, which is commonly referred to as edges. The last branch doesn’t expand because that is the leaf, end of the tree. In this case, it is represented as red or green, whether the passenger has survived or not.
Albeit, there will be more than 3 features in huge datasets and this will just be one branch but we can’t ignore the simplicity of the algorithm.
The can be used to solve both, classification and regression problems. And in general decision tree algorithms referred to as CART or Classification and Regression Trees.
Behind the Scenes of Decision Tree Machine Learning
Decision Tree Learning – Recursive Binary Splitting
It is the procedure in which all the columns/features are considered and different split points are tried and tested using a cost function and the split with the lowest cost is selected.

Let’s consider the previous decision tree machine learning example of the Titanic dataset. In the first split, from the root, all features are considered and training data is divided into groups based on the split.
We have 3 features so we will have 3 splits. Now we will find the cost of each using a function (we will see later on how the cost function works). As discussed earlier the split with the least cost is chosen, in our example, it is the gender of the passenger.
In addition, this algorithm is recursive in nature so the groups formed can be further sub-divided using the same strategy.
Due to this strategy, this algorithm is also known as a greedy algorithm, as we have an excessive desire to find the least cost.
Decision Tree Learning – Cost of Split
Let us talk about the cost function used for both, classification and regression. In both techniques, the cost function is trying to find similar branches.
Regression: sum(y — prediction)²
To exemplify, let’s say we are predicting the price of houses. Now as discussed earlier, the decision tree will start splitting by considering each feature.
The mean responses of a particular group are considered as a prediction for that group. The function mentioned above is applied to all data point and the cost is calculated.
Classification : G = sum(pk * (1 — pk))
This is the equation of calculating the Gini score. Gini score gives an idea of how good a split is. Here, pk is the proportion of same class inputs present in a particular group.
A perfect class purity occurs when a group contains all inputs from the same class, in that case, pk is either 0 or 1 and G=0.
Decision Tree Learning – When to Stop Splitting
Just like in the stock market you must know when to exit to book maximum profit or minimum loss, in the decision tree, you must know when to stop splitting.
With large datasets comes a large set of features which brings high complexity to the trees and there is a chance of overfitting.
Hence, we need to know when to stop. One way of doing this is to set a minimum number of training inputs to use on each leaf.
For example, we can use a minimum of 10 passengers to reach a decision, so we ignore any leaf that takes less than 10 passengers. On the contrary, another way is to set the maximum depth of your model.
A Step Further Decision Tree Learning — Pruning

To further increase the performance of the tree we use the method called pruning. It is basically removing the branches that make use of feature having low importance.
Doing this reduces the complexity of the tree, thus increasing its predicting power by avoiding overfitting.
The simplest method of pruning starts at leaves and removes each node with the most popular class, it is referred to as reduced error pruning.
More sophisticated pruning methods can be used such as cost-complexity pruning, where a learning parameter called alpha is used to weigh whether nodes can be removed. It is sometimes referred to as weakest link pruning.
Advantages of CART
(i) Simple yet easy to understand, interpret and visualize.
(ii) They implicitly perform feature selection.
(iii) They can handle both the data type, categorical and numerical.
(iv) It can also handle multi-output problems.
(v) It requires relatively little effort from users for data preparation.
(vi) The non-linear relationship between parameters does not affect the performance of the tree.
Disadvantages of CART
(i) Novice decision-tree learners can create complex trees that do not generalize the data well. This is a problem called overfitting.
(ii) Small variations in the data might result in a completely different tree being generated hence Decision trees can be unstable. This is called variance, which needs to be lowered by methods like bagging and boosting.
(iii) Globally optimal decision trees are not guaranteed with greedy algorithms. This can be mitigated by training multiple trees, where the features and samples are randomly sampled with replacement.
(iv) Decision tree learners create biased trees if some classes dominate, meaning it has more weight than others. It is therefore recommended to balance the data set prior to fitting with the decision tree, not just in decision trees but for all machine learning problems.
End Notes
There it is. All the basics to get you to par with decision tree learning, decision tree machine learning example & learning decision trees in artificial intelligence.
Machine Learning is evolving day by day, you better start today if you want to on track. Scikit-learn is a popular library for implementing these algorithms.
It provides wonderful API that can get your model up and running with just a few lines of code in python.
In addition find this decision tree machine learning pdf from Princeton University, which is a good resource to start with. So, what are you waiting for? Grab some data and get started.
If you are too looking for building a career in Machine Learning, enroll in our Machine Learning using Python Course.
Happy Learning.

















