
Artificial Neural Networks are composed of simple units. Each unit usually does a very simple calculation like an addition or an application of a simple function. It takes input from many other neurons and sort of agglomerates that data that comes in and sends it downstream to other neurons. These things are connected in a kind of network. Every single computer on the planet operates through algorithms.
Algorithms are mathematical recipes that instruct a computer to complete a certain task. Algorithms usually give a very specific set of instructions that leaves nothing to interpretation. What makes machine learning different from this old framework is that in this case algorithms can change their own instructions to improve the function of the computer and this is really the core of artificial intelligence.
While regular machines excel in speed and accuracy, they are limited by their program parameters. Human intelligence, on the other hand, is way more adaptable so in order to truly achieve artificial intelligence, computers have to think adaptively and there have been many approaches towards making computers more competitive against the human brain but some computer programmers concluded that well if you can’t beat them join them.
One popular technique to generate artificial intelligence is in fact designed to work like the human brain and the nervous system, it’s called artificial neural networks. The following text is generated by a recurrent neural network by Ryan Kiros. This is based on an input image data. (You can find it at the end of this post)
Only Prince Darin knew how to run from the mountains, and once more, he could see the outline of rider on horseback. The wind ruffled his hair in an attempt to locate the forest. He had’nt been in such a state of mind before, but it was a good thing. [..] The wind blew up the mountain peaks and disappeared into the sky, leaving trails behind the peaks of the mountains on Mount Fuji.
The Beginning…

The 20th-century art had essentially been liberated from the role of making accurate representations and free to go and explore incredibly interesting new ways of depicting things. The codec process in the meantime commoditized photography and people started very quickly making art and indeed today fine art photography is alive.
Hundreds of millions of dollars of revenue and turnover in terms of art sales and indeed painting has sort of come full circle. There are now techniques such as hyperrealism which incorporate photography as part of the painting process, somewhat completely different artificial neural networks. New networks are a form of computing which has its beginnings in the 1940s when people started thinking about the brain as a computer and thinking about how it might work.
For example one of those people was Alan Turing and a not very well known essay from 1948, he proposes a computing architecture based on this idea that you could have these very simple units like neurons which would make very simple calculations based on connections from other neurons and that the connections would be tunable, essentially so his idea was that this machine would be at first unorganized.
He called this a deform unorganized machine and then through training, it would organize itself in order to do the task at hand. In most of the 20th century, the sort of expert system and rule-based systems were better at solving difficult computational tasks. For example, computer vision problems or other like language translation and parsing.
But the last five to ten years, there has been an incredible revival of artificial neural networks in this field and indeed most sort of cutting-edge technology in this field. A part of this change was algorithmic and part of the changes that we have more data now but a big part of this change has been the commoditization and sort of the advent of cheap parallel processors which are very good at the kinds of calculations you need for artificial neural networks. This was a brief introduction to artificial neural networks. Next, I will talk about the classification process by giving a real-world artificial neural network example.
Classification Process in Artificial Neural Networks – Cuter than kittens and pups

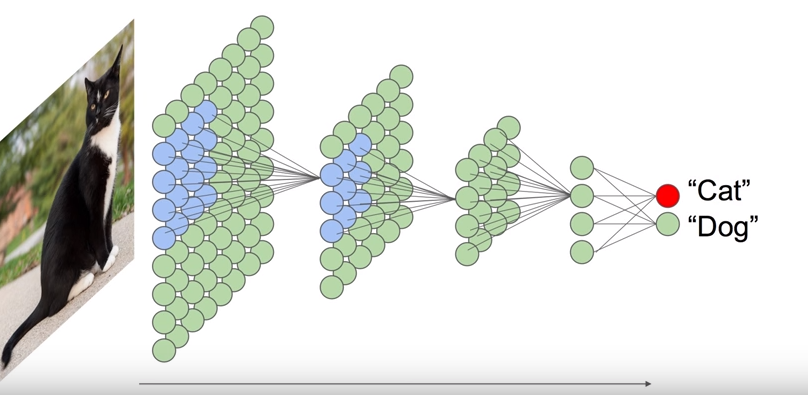
About this artificial neural network example, here is a classic computer vision problem where you have pictures and you want to basically classify the pictures. To do that you want to have a computer program that can tell whether the picture is a picture of a cat or a dog so when you try and solve this kind of problem with the neuro-network this kind of architecture is often used. It’s in layers where each layer only connects to the next layer.
The information from the picture i.e. the pixel data is fed into the input layer and then the next layer sort of takes that information and processes it and passes on to the next layer. The weights that connect and neurons have this sort of connections that connect the neurons that have weights associated with them and those weights are random at first. So just like Alan Turing proposed, at first this machine is unorganized and it doesn’t work.
If you showed a picture, it will randomly give an answer on the other side. But way typically on the far side of the network you have sort of fewer and fewer neurons and at the end, you might just have a very small number that represents sort of the results that target classes. In this case, it would be to say cat or dog. When you feed information through the network it runs through like as shown in the diagram and then you get some answer.
Now at first this doesn’t work, we need to train the network and this is basically the essence of the thing. These kinds of machines are capable of extracting the salient features from any kind of input data. In this case – pictures, so we would show the network thousands and thousands of examples of cats and dogs and each time we would tell the network this is a cat and this is a dog and if it gives the wrong answer which at first it will do all the time, you adjust the weights of the network in such a way as to isolate the correct answer.
You do this over and over again in an iterative way you end up with a computer program that can distinguish pictures of cats and dogs even in cases where it’s never seen that particular pictures before and that’s kind of the point it generalizes what makes a cat on what makes a dog. Image recognition based on this training model is one of the most significant artificial neural network application.
How “It” works?
What’s remarkable is that it itself organizes in such a way that the layers are close to the input data, basically the neurons in those layers become reactive to simple features like edges, corners or combinations of them and then as you move through the layers the features that the neurons respond to become of higher and higher order.
They would react to like a long line or a square and then further up they might be complete features like the hubcap or an eye and then right at the end of the network the neurons respond to really complex features like a cat. Interestingly we have found very similar things in our own brains in the visual system for different layers also extract higher and higher order features once you have a network that’s trained.
This way it should be possible to also run this thing backward. If you have a thing that knows everything about what a cat is like, it should be able to produce new pictures that look like cats or dogs and so these are called sort of generative artificial neural networks.

Let me explain this further by giving a real-world artificial neural network example, one of them started with experiments by Alexander Mordvintsev at Google, he was interested to create visualizations of the internal knowledge sort of stored in the neural network and he came up with this really neat algorithm where you show a network that’s trained on whatever a picture you run the network forward and then you basically adjust the pixels in the image towards that interpretation just a little bit and if you do this over and over again you get these kinds of images.
Suddenly the photograph fills with all these interesting impressions the new network knew about. It’s almost like cloud watching, the slightest suggestive features suddenly turn into dog faces and cars and buildings. If we sort of keep zooming into the picture so you get this really interesting sort of fractal world appear where the network keeps over-interpreting and the image keeps on going forever, essentially you can just keep going.
What’s interesting too is that depending on where you do this in the network it reveals sort of the level of the kind of features that that layer cares about so the early layers may care about very simple features lines and edges and so forth and you get pictures that are composed of those kinds of things. As you move through the network you get higher and higher-order features, windows or mountain ranges or entire concepts like building subtrees.
These images are just serve spewed out by the network based on the rules that are extracted from natural images that it saw during training. You can also ask a different question you can say okay well what is this one neuron care about like what does it respond to so if you optimize images with respect to a single neuron you get much more focused kind of things. Deep Dream is a very significant artificial neural network application. (Refer the description of the image below)

Bias in Artificial Neural Networks
Imagine that you stub your toe, there are sensory nerves in your foot that set off a chain reaction of signals that ultimately tells your brain but you just felt pain and ideally, this is how neural network should work. This program is comprised of a series of branching notes that operate much like the neurons in your body. Computer programmers feed information to input nodes which then transmits the information across the entire complex.
This network then processes this information until it generates the desired output. So how does this network do that? though neural networks are inspired by two essential components of the human brain the neuron and the synapse. A neuron is a type of cell that processes the information that receives from other neurons. The synapse is the connection between neurons allowing information to flow from one neuron to another.
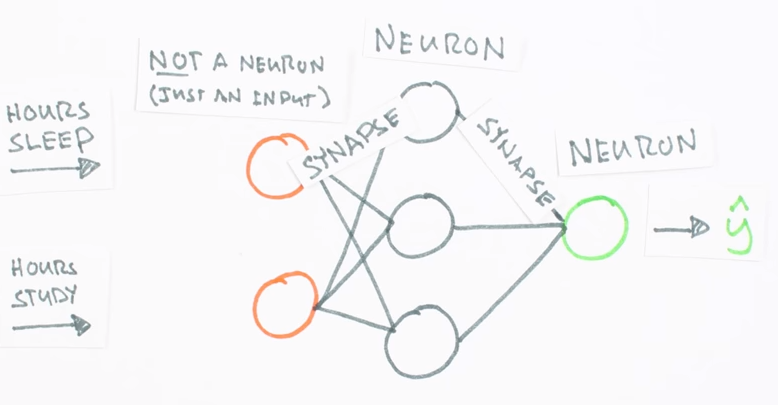
These computer programs have their own version of each. In neural networks, the node acts like a neuron that receives information, performs a quantitative function that transforms the information. A synapse carries its information from one node to another making its own adjustments to the data as well.
When a node sends out a signal it synapses a lot of information by multiplying the data by some constant value, this modifying step is called applying weight and though it can accumulate data from multiple synapse connections and adds up all this information together before processing it then just like the synapses they do and make adjustments to the data by multiplying it by value and this is called node bias.
Our infant data is subjected to weights and biases because this determines whether the information is transmitted from one node to another, it acts like a checks and balances system. In order for one node to pass along data, it needs to be activated first. Nodes are activated when its output is big enough to pass a certain threshold determined by the computer programmer.
If your data reaches past a certain point it will move on to the next node, if not the node in this series of activation turning those on and off is that the term is the ultimate product of your network and this is how networks tell the difference between pictures of cats and dogs but what if the final product isn’t what you wanted? what if your neural network accidentally claims the dog to be a cat?
If the output leaves something to be desired the neural network uses another process called backpropagation to go back and adjust its weights and biases fine-tuning its nodes and synapses little by little until it gets a result as close to correct. As it gets more data and feedbacks the neural networks gets more accurate. From this basic model, computer programmers train neural networks to be better chess players or to recognize voices or to identify your doodles. This is a very simple model though as most artificial neural networks contain thousands of neurons.
Training
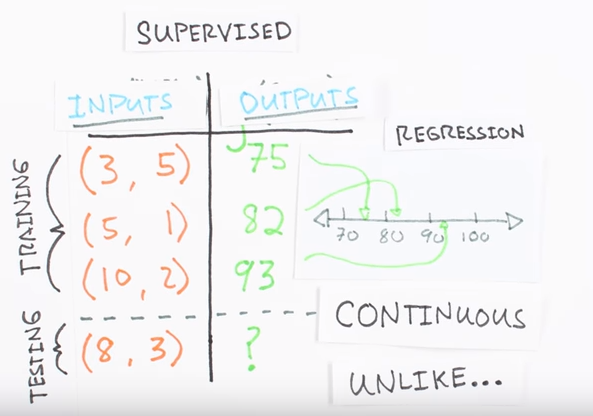
Let’s say you want to predict some output value ‘Y’ given some input value ‘X’. For example, maybe you want to predict your score on a test based on how many hours you sleep and how many hours you study the night before. To use a machine learning approach we first need some data, let’s say for the last three tests you recorded your number of hours studying your number of hours sleeping and your score on the test. We’ll use the programming language Python to store our data in two-dimensional empire raids. Now that we have some data we’re going to use it to train a model to predict how well you will do on your next test based on how many hours you sleep and how many hours you study, this is called a supervised regression problem. It’s supervised because our examples have inputs and output. It’s a regression problem because we’re predicting your test score which is the continuous output. If we were predicting your letter grade this would be called a classification problem and not a regression problem. There are an overwhelming number of models within machine learning.
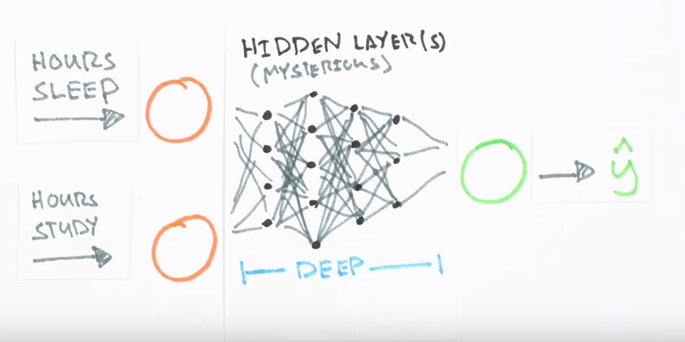
Here we’re going to use a particularly interesting one called an artificial neural network. These are loosely based on how the neurons and your brain work and have been particularly successful recently at solving really big, really hard problems. Before we throw our data into the model we need to account for the differences in the units of our data both of our inputs are in hours but our output is a test score scale between.
Neural networks are smart but not smart enough to guess the units of our data, it’s kind of like asking our model to compare apples to oranges. Most learning models really only want to compare apples to apples. The solution is to scale our data in a way our model only sees standardized units. Here we’re going to take advantage of the fact that all our data is positive and simply divide by the maximum value for each variable effectively scaling our result between zero and one. Now we can build our neural network.
We know our network must have two inputs and one output because these are the dimensions of our data. We’ll call our output layer ‘Y’ hat because it’s an estimate of ‘Y’ but not the same as ‘Y’. Any layer between our input and output layer is called a hidden layer. Recently researchers have built networks with many many hidden layers, these are known as deep belief networks, giving rise to the term deep learning.
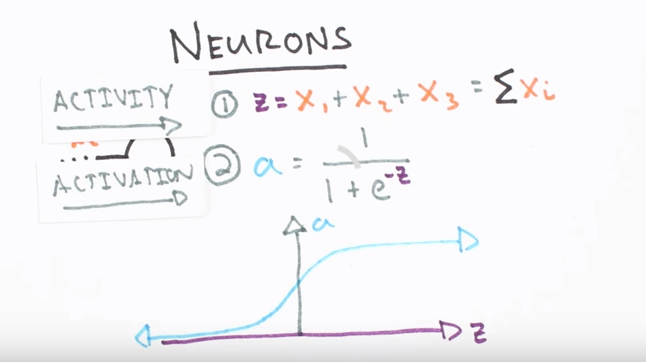
Here we’re going to use one hidden layer with three hidden units but if we wanted to build a deep neural network, we would just stack a bunch of these layers together in a neural net. Visual circles represent neurons and lines represent synapses. Synapses have a simple job, they use a value of their input and multiply it by a specific weight and output the result.
Neurons are a little more complicated, their job is to add together the outputs from all their synapses and apply an activation function. Certain activation functions allow neural networks to model complex non-linear patterns that simpler models may miss. For our artificial neural network application, we will use sigmoid activation functions. We can then build our neural net in Python.
The End…
We’ve formed millions of connections and yet even the most sophisticated artificial neural networks are still in the Stone Age compared to the human brain that is close to hundred billion neurons. We’ve made big advances in artificial intelligence but we need to be reminded every so often that we’re still pretty far away from the real thing.

Deep Dive
I have collected some resource material such as PDFs/e-books and PPTs which you can refer if you want to deep dive and know everything there is to artificial neural networks. These PDFs and PPTs will cover all the topics in detail like – an artificial neural network in artificial intelligence, artificial neural network tutorials, what is an artificial neural network, a lot more artificial neural network examples, artificial neural network definition, types of artificial neural network and so on. If you own an Amazon Kindle device, you can buy the kindle version of the e-books directly from the Amazon India website.
Neural Networks by D. Kriesel [Raw PDF]
http://www.dkriesel.com/_media/science/neuronalenetze-en-zeta2-1col-dkrieselcom.pdf
Neural Network: A Brief Overview by Torsten Reil [PPT]
www.d.umn.edu/~alam0026/NeuralNetwork.ppt
Make Your Own Neural Network by Tariq Rashid [PDF/e-book for Kindle]
Machine Learning with Neural Networks (PDF/e-book for Kindle)
Neural Networks: Artificial Neural Networks. Concepts, Tools and Techniques explained for Absolute Beginners (Data Sciences) [PDF/e-book for Kindle]
The content concept, excerpt, quotes and image credits:
TED Talk by Mike Tyka (Artist, Scientist, Glass Casting, Copper Sculpture, Googler | @mtyka )
Recurrent neural network by Ryan Kiros, University of Toronto
Video Presentation titled “Neural Networks Demystified” by Welch Labs | @stephencwelch
Video Presentation on Neural Networks by Olivia Trani
DeepDream by Google engineer, Alexander Mordvintsev
-Ends

















