
Machine learning is about teaching a computer to perform specific tasks based on inferences drawn from previous data. You do not need to provide explicit instructions.
However, you do need to provide sufficient data to the algorithm to train it.
The data is initially in a raw form. You need to extract features from this data before supplying it to the algorithm. This process is called feature engineering.
Collecting, cleaning and engineering the data is the hardest part of the machine learning process.
What is Feature Engineering?
Even the raw dataset has features. Most of the time, the data will be in the form of a table.
Each column is a feature. But these features may not produce the best results from the algorithm.
Modifying, deleting and combining these features results in a new set that is more adept at training the algorithm.
Feature engineering in machine learning is more than selecting the appropriate features and transforming them.
Not only does feature engineering prepare the dataset to be compatible with the algorithm, but it also improves the performance of the machine learning models.
Importance of Feature Engineering for Machine Learning
Do you know that data scientists spend around 80% of their time in data preparation?
Feature engineering is a vital part of this. Without this step, the accuracy of your machine learning algorithm reduces significantly.
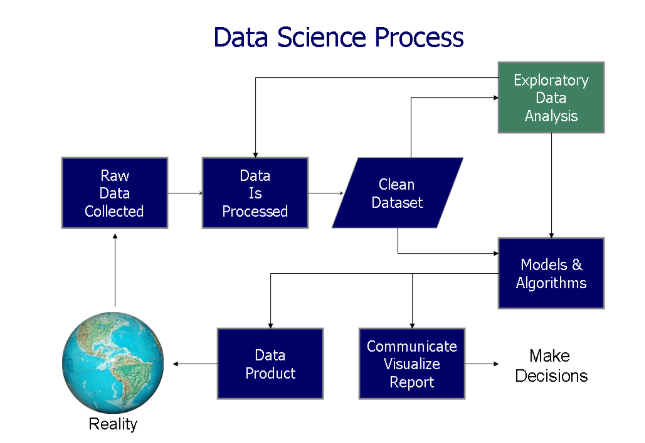
A typical machine learning starts with data collection and exploratory analysis. Data cleaning comes next. This step removes duplicate values and correcting mislabelled classes and features.
Feature engineering is the next step. The output from feature engineering is fed to the predictive models, and the results are cross-validated.
An algorithm that is fed the raw data is unaware of the importance of the features. It is making predictions in the dark.
You can think of feature engineering as the guiding light in this scenario.
When you have relevant features, the complexity of the algorithms reduces. Even if you use an algorithm that is not ideal for the situation, the results will still be accurate.
Simpler models are often easier to understand, code, and maintain.
The winning teams in Kaggle competitions admit to focussing more on feature engineering and data cleaning.
The most valid answer to the question – what is feature engineering is that it is a guide to your algorithms.
You can also use your domain knowledge to engineer the features and focus on the most relevant aspects of the data.
Feature Engineering Techniques
There are different ways to perform feature engineering. Some of them are better suited for some algorithms or datasets.
Some work equally well in all situations. Practice and experience will teach you which technique should be used where.
Here are some of the basic techniques every machine learning beginner should be aware of.
1. Imputation
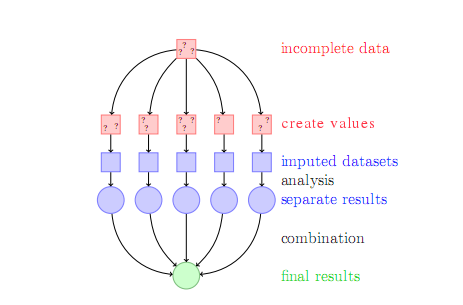
The dataset is not always complete. Values may be missing from the columns. Imputation is used to fill in the missing values.
The simplest way to perform imputation would be to fill in a default value. The column may contain categorical data. You can assign the most common category.
If the ML algorithm has to make accurate predictions, the missing training data should be filled with a value that is as close to the original as possible. You can use statistical imputation for this.
Here, you are creating a predictive model within another predictive model. The complexity can become uncontrollable in such cases.
Therefore, the imputation method should be fast and its prediction equation should be simple. You should also ensure that the predictor for the missing data is not too sensitive to outliers.
K-nearest neighbors, tree-based models, and linear models are some of the most common techniques used for imputation.
2. Handling Outliers
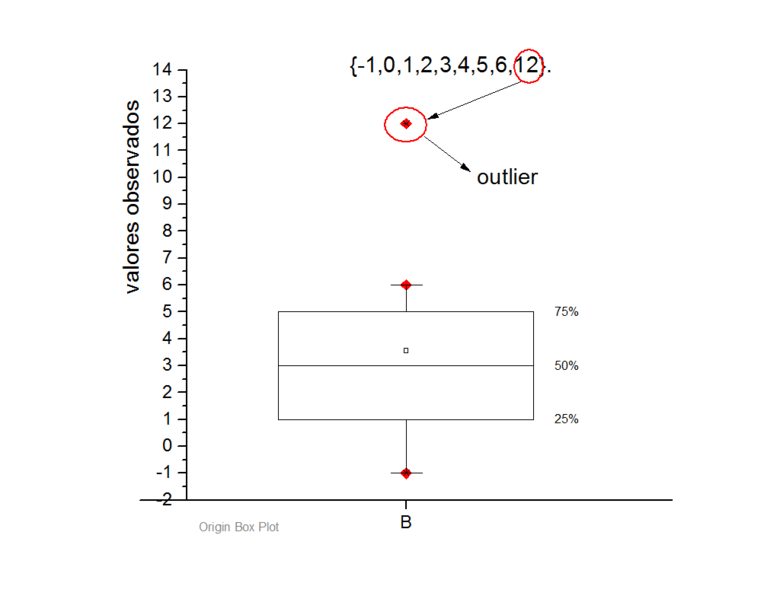
Any observation that is too far from the rest is known as an outlier. It impacts the predictive models and distorts the results. The first step in handling outliers is detecting them.
You can use box plots, z-score, or Cook’s distance to identify the outliers.
When it comes to recognising outliers, visualisation is a better approach. It gives more accurate results and makes it easier to spot the outliers.
The outliers can be removed from the dataset. But this also reduces the size of your training data. Trimming the outliers makes sense when you have a large number of observations.
What is a feature engineering technique that can be used to solve this problem? You can also Winsorise the data or use log-scale transformation on it.
Models such as Random Forests and Gradient Boosting are resilient to the impact of outliers. If there are too many outliers, it makes better sense to switch to these tree-based models.
3. Grouping Operation
Every feature has different classes. Some of these classes may only have a few observations. These are called sparse classes. They can make the algorithm overfit the data.
Overfitting is a common pitfall in ML models that needs to be avoided to create a flexible model. You can group such classes to create a new one. You can start by grouping similar classes.
Grouping also works in a different context. When some features are combined, they provide more information than if they were separated. These features are called interaction features.
For example, if your dataset has the sales information of two different items in two columns and you are interested in total sales, you can add these two features. You can multiply, add, subtract, or divide two features.
4. Feature Split
Feature splitting is the opposite of grouping or interaction features. In grouping operations, you combine two or more features to create a new one.
In feature splitting, you split a single feature into two or more parts to get the necessary information.
For example, if the name column contains both first and last name but you are interested only in the first name, splitting the name feature into two would be a better option.
Feature splitting is most commonly used on features that contain long strings. Splitting these make it easier for the machine learning algorithm to understand and utilize them.
It also becomes easier to perform other feature engineering techniques. Feature splitting is a vital step in improving the performance of the model.
5. Binning
Binning transforms continuous-valued features into categorical features. You can group these continuous values into a pre-defined number of bins.
Binning is used to preventing overfitting of data and make the model robust. However, binning comes at a cost. You end up losing information, and this loss can negatively impact the performance of the model.
You need to find a balance between overfitting and improved performance. Consider the number of views per video on Youtube.
It can be abnormally large for some videos or extremely low for some others. Using this column without binning can lead to performance issues and wrong predictions.
The bins can have fixed or adaptive width. If the data is distributed almost uniformly, then fixed-width binning is sufficient. However, when the data distribution is irregular, adaptive binning offers a better outcome.
6. Log Transform
Is your data distributed normally? Or is it skewed? A skewed dataset leads to inadequate performance of the model.
Logarithmic transformations can fix the skewness and make the model close to normal. Logarithmic transformation is also helpful when the magnitude order of the data within the same range.
Log transformation also reduces the effect of outliers. Outliers are a common occurrence in many datasets. If you set out to delete all outliers, you also end losing valuable information.
When your dataset is small in size, deleting outliers is not the ideal solution.
Log transformation retains the outliers but reduces the impact they have on the data. It makes the data more robust.
Keep in mind that the log transform only works for positive values.
If your data has negative values, then you need to add a constant to the whole column to make it positive and then use this technique.
The Scope of Feature Engineering in Machine Learning
Feature engineering in machine learning is a vast area that includes many different techniques.
But quite a lot of it is also about using your intuition. You need to have a good knowledge of the domain.
Understanding the field where the problem originates is crucial in helping you perform feature engineering.
Applying the techniques blindly, without a clear picture of why you need to do it can cause more harm than good. As seen above, a few of the techniques rely on finding a balance.
Only when you understand why it is better to retain outliers rather than delete them or why binning is the right strategy will you be able to develop a predictive model that is resilient, flexible and robust.
Feature engineering in machine learning is more than learning all the techniques and applying them. This is one of those things that you become better at by practicing.
The more machine learning problems you solve, the better your feature engineering will become.
Here is a video to help you understand more about feature engineering techniques.
Wrapping Up
Are you intrigued to know what is feature engineering? Would you like to learn more about feature engineering and other aspects of machine learning?
Enrol in one of Digital Vidya’s Machine Learning using Python Course today! The Government of India certified courses have a relevant curriculum and are handled by industry experts.
The project you would do during the duration of the course is also designed to make you a better data scientist. Expand your career by stepping into the world of data science with Digital Vidya.

















