
What is Machine Learning really?
As you probably know, there are several forms of Machine Learning, here in this article we will learn what each form has to offer. We will first start with defining Machine Learning. The most reliable definition fount on the internet is: “the field of study that gives computers the ability to learn without being explicitly programmed.” However, this is an older, informal definition.
Tom Mitchell provides a more modern definition, which is: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.“
Checkers
Scratching your head? Don’t worry, let’s take an example and break it down, for instance, playing checkers, where
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
If the performance of machine playing checkers, measured by how many games it wins, improves with playing many games of checkers, we can say that the machine is learning by itself, which is Machine Learning.
So, how to identify problems of Machine Learning? In general, there are two types of machine learning algorithms, Supervised Machine Learning and Unsupervised Machine Learning. In addition, new categories evolve with development in the field which can be identified as reinforcement learning. Let’s dive into what these categories are and how they work.
Supervised Learning – First form of Machine Learning
In supervised learning, we are given a data set and already know what our correct output should look like. We are having the idea that there is a relationship between the input and the output. Supervised learning problems are further categorized into regression and classification problems.
Regression
In a regression problem, we are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function. To exemplify, given data about the size of houses on the real estate market, try to predict their price. Another example would be, given a picture of a person, we have to predict their age or gender.
Classification
Classification, on the other hand, is finding the category of the input variable, or in more academic terms, mapping input variables into discrete categories. Ideal sentence to find a classification problem would be, whether this or that, like, yes or no, 0 or 1, true or false. For example, from the example of house price given above, if we change the output to “Sells for more or less than asking price,” then it is a classification problem. Another example is, given a patient with tumour, we have to predict whether the tumor is malignant or benign.
How Supervised learning works
To describe the supervised learning problem slightly more formally, our goal is, given a training set, to learn a function h : X → Y so that h(x) is a “good” predictor for the corresponding value of y. For historical reasons, this function h is called a hypothesis. Seen pictorially, the process is therefore like this:
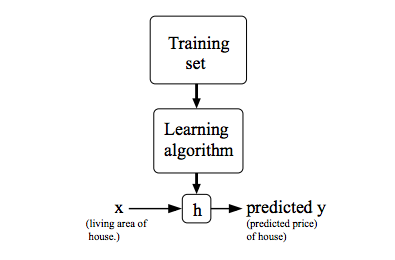
When the target variable that we’re trying to predict is continuous, such as in our housing example, we call the learning problem a regression problem. When y can take on only a small number of discrete values (such as if, given the living area, we wanted to predict if a dwelling is a house or an apartment, say), we call it a classification problem.
Algorithms
There are plenty of different algorithms to solve different kind of problems. There is no right or wrong in the algorithms, it is just some apply to some problems better than the others. Supervised machine learning algorithms include Linear regression, Logistic regression, Random forest, KNN, Decision tree and so on. Let’s understand how these machine learning supervised learning algorithm works,
Linear Regression
Linear regression is simply estimating real values based on continuous variable(s). In more technical terms, we establish a relationship between independent and dependent variables by fitting the best line (real estate example). This line is known as the regression line, which is represented by a linear equation, Y = a*X + B, where,
Y— Dependent variable
a— Slope
X— Independent variable
b— Intercept
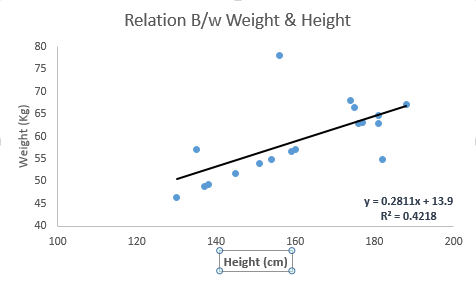
Moreover, Linear regression is mainly two types, simple and multiple. In simple, there is only one independent variable, whereas in multiple, as the name suggest, there are more than one independent variable.
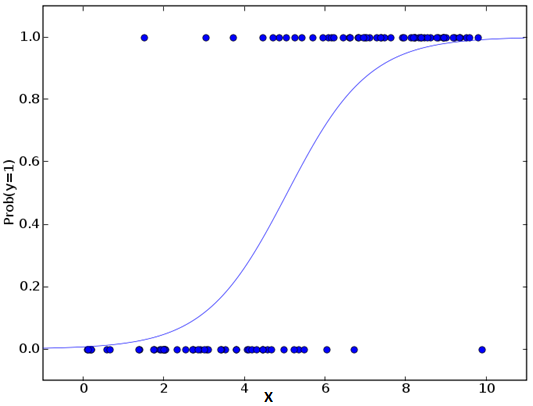
Logistic Regression
Logistic Regression is a classification algorithm, don’t confuse with its name. It estimates discrete values based on independent variable(s). Since it predicts the probability of occurrence of a particular event by fitting data to a logistic function, output is as expected between 0 and 1.
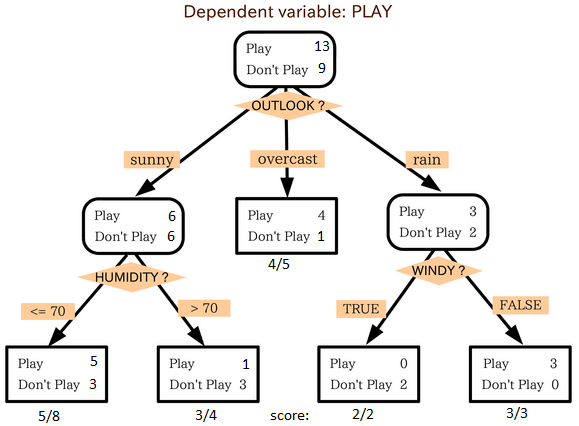
Decision Tree
This is the most favorite algorithm of all times. It is used mainly for classification problems and is, of course, supervised algorithm having pre-defined target variable. In this algorithm, we split the sample into two or more sub-parts based on the most significant differentiators in input variables, which is done by various techniques like Gini, Chi-square, entropy etc.
Unsupervised Learning- Second form of Mchine Learning
On the contrary to Supervised learning, Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don’t necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data. With Unsupervised learning, there is no feedback based on the prediction results. For example, take a collection of 1,000,000 different genes, and find a way to automatically group these genes into groups that are somehow similar or related by different variables, such as lifespan, location, roles, and so on. This is a good example of clustering. Whereas, for a non-clustering problem such as “Cocktail Party Problem”, it helps in identifying voices music from a mesh of sounds at a cocktail party.
Algorithms
Unsupervised learning algorithms help in a wide range of problems such as Social Network Analysis, Astronomical Data Analysis, and so on. Google news is using this approach as well. Neural networks are a part of unsupervised learning. Let’s understand how few of them works.
K-means (Clustering)
The goal of clustering is to create groups of data points such that points in different clusters are dissimilar while points within a cluster are similar. With k-means clustering, we want to cluster our data points into k groups. A larger k creates smaller groups with more granularity, a lower k means larger groups and less granularity.

Reinforcement Learning – Third form of Machine Learning
Reinforcement Learning is, when exposed to an environment, how the machine train itself using trial and error. The machine mainly learns from past experiences and tries to perform the best possible solution to a certain problem. In the past couple of years, a lot of improvements in this particular area have been seen. Main example includes DeepMind’s Alpha Go, beating the champion of the game Go in 2016.
The Reinforcement Learning Process
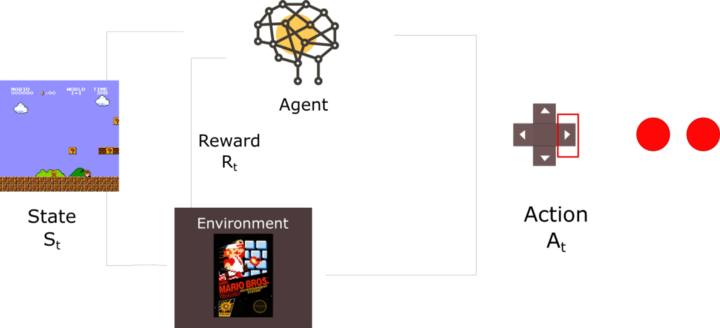
Let’s understand the learning process of machine/agent by the example of agent learning to play Super Mario Bros. The process can be modeled as a loop that works like this,
- Agent receives state S0 from the environment, which in our case is, the first frame of our game.
- Based on that state S0, agent takes an action A0, moving right/foreword.
- Right after that the environment transit to a new state S1, which is basically a new frame.
- Environment gives some reward R1 to agent (not dead: +1)
Endnotes
By now, I am sure that you have enough idea about the different machine learning types and algorithms to get you started. Machine Learning is a field in which you learn 4 times faster by doing it rather than studying it. I would suggest take up small problems and develop your idea about how you can solve the same with Machine Learning, then find an appropriate algorithm to solve it and have fun.
If you are also looking forward to building a career in Machine Learning, enroll in Digital Vidya’s Machine Learning Course to become an expert.
Do let us know in the comments if you have any doubt regarding anything written up there, we are happy to help.
Happy learning.

















Hello, I have to implement machine learning algorithms in python so could you help me in this. anybody provide me the proper code for an algorithm.