
Data is surely going to stay with us till the next big bang happens, and not only staying but growing exponentially. Storing and processing that data to help grow humanity is really crucial and important. Hadoop provides a solution to our questions about the enormous amount of data by its ability to store and analyze huge amounts of any kind of data, quickly!, it’s computing power, fault tolerance and of course low cost!
Why was HDFS (Hadoop Distributed File System) needed?
There is a simple way to look at it. Even after the storage capacity of hard drives has elevated abundantly over the years, access speeds – the rate at which data can be read from the drives – remains the same as earlier.
For example, in the 90s, a particular drive could store 1,370 MB of data and had a transfer rate of 4.4MB/s. So, one could read all the data from that drive in around five minutes. In the 2010s, one typical drive could store 1 TB of data, and the transfer rate is around 100 MB/s. So, it takes two and a half hours to read all the data on the drive. It is considered a long time to read/write from the disk.
Now here is the problem- access rate of data. There is an easy way to solve this. Reduce the time by reading the data simultaneously from multiple disks. Let’s say, for a total of 100TB of data, you have 100 drives, each holding 1TB of data. Working in parallel, it will reduce the time to read and write data remarkably.
There are mainly two issues which Hadoop overcomes with one technique or another.
HDFS Explained
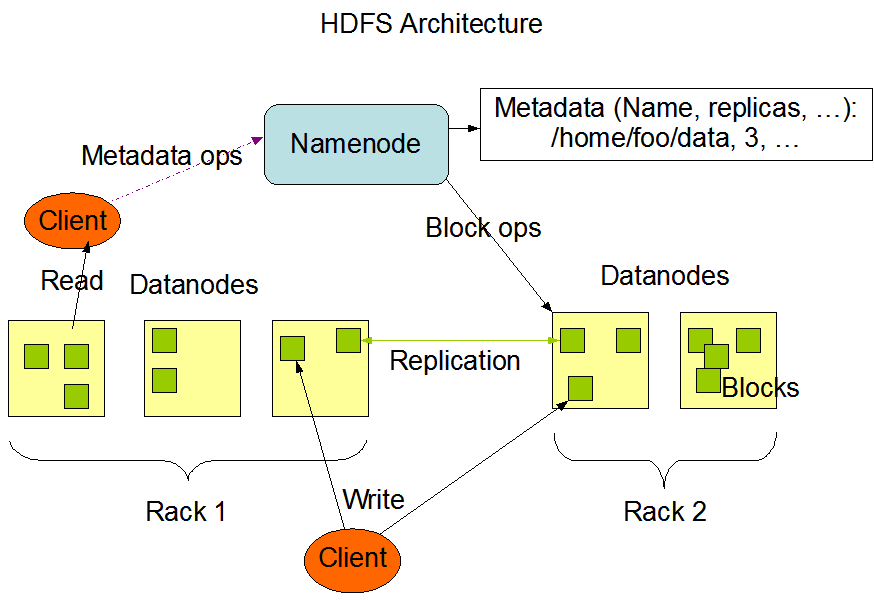
The first problem is- Hardware failure rates are high (as data is being stored in the only single device, the chance that hardware of the device will fail is fairly high). A common way to avoid loss of data is to take a backup of data in the system. So that in the event of failure, there is another copy of data available. This is how RAID works, but HDFS (Hadoop distributed file system) takes a slightly different approach.
Hadoop traditionally comes with a distributed file system called HDFS. Hadoop by default stores 3 copies of each data block in the cluster on different nodes of the cluster. Any time a node or machine fails containing a certain block of data, another copy is created on another node in the cluster thus making the system fail-proof.
“HDFS is a filesystem designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware.”
Let us understand the definition by breaking it into parts,
“Very large” in this definition means files that are hundreds of gigabytes or terabytes in size. Currently at Yahoo!, there are Hadoop clusters running which stores petabytes of data.
“Streaming data access.”
HDFS follows a write-once and read-many-times pattern. A single dataset is generated or copied from the source, and then the various analysis is performed on the dataset. Each analysis will involve a large proportion of the dataset. So, the time to read the whole dataset is important than in reading the first record.
“Commodity hardware.”
Hadoop doesn’t require expensive hardware. It is designed to run on clusters of commodity hardware (Affordable and Easy to obtain). HDFS is designed to handle such node failures.
Map-Reduce Programming Model
The second problem is that most analysis techniques need to be able to combine the data in some way. Like, data from disk 1 may need to be combined with the data on disk 4 which in turn may need to work with data on disk 9 and 12. Combining data from different disks on the fly during the analysis can be a challenging task.
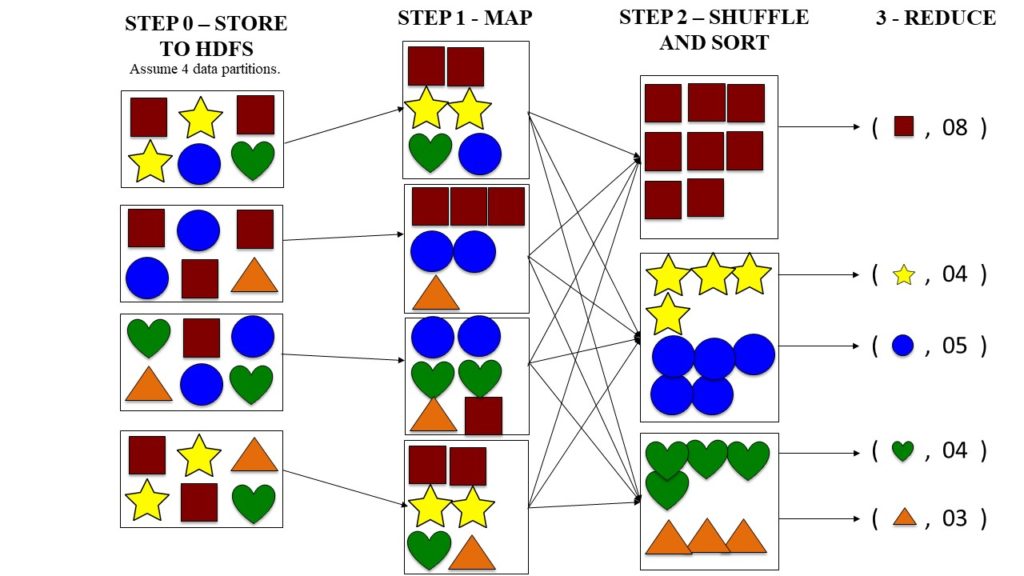
Map-Reduce provides a programming model that provides ease in combining data from all the drives. There are mainly 2 parts in the model – the map phase and the reduce phase—and it’s the interface between these 2 where the process of “combining” data occurs.
Map-Reduce is a good fit for applications that need to analyze the whole data set in a batch fashion. It is not suitable for interactive analysis which means, you can’t run a query and expect the answers in a few seconds or minutes. Responses to queries sometimes can take minutes or more, so Map-Reduce works better for offline use (where a human isn’t waiting for the answer to the queries).
YARN Explained
The elementary idea about YARN(Yet Another Resource Manager) is to split the functionalities of resource management and job scheduling in to separate daemons. Let’s break this into two parts for better understanding, first, Classic Cluster- which is two or more connected computers- and second, YARN cluster.
Cluster
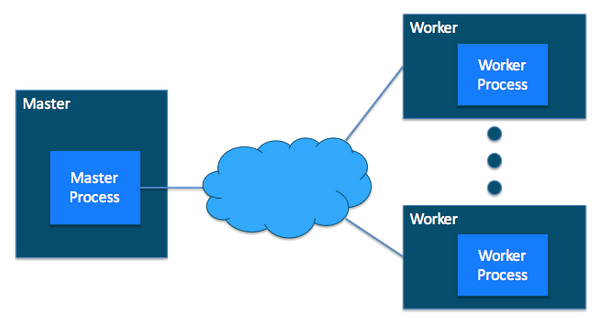
In Hadoop, a computer is known as a Host and in YARN the same is denoted as a Node. Hence, two or more Hosts, connected by a local high-speed network creates a cluster. From the viewpoint of Hadoop, there may be several thousand hosts in a cluster.
Now further host can be divided into two parts, Master and Worker. Ideally, as the name suggests, Master Host-only communicates with the client and sends the work to the rest of the cluster in which all the worker hosts are.
YARN Cluster
Now that you know what a cluster is and how it works, let’s dig dipper in YARN cluster, just like a classic cluster, YARN cluster also consists of two types of host,
- A Resource Manager is the master daemon- a background process that handles requests for services- that communicates with the consumer, trail resources on the cluster, and arrange work by assigning tasks to Node Manager.
- A Node Manager is worker host that launches and tracks on worker host.
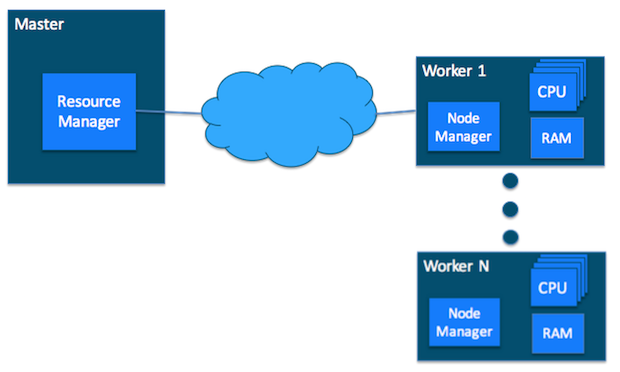
Other than the basics, there are some important elements of YARN you should know about.
- A container holds the resources on a cluster.
- The configuration file for YARN is called yarn-site.xml and the copy of this file is there on each host in the cluster.
However, there are some challenges in using Hadoop.
- Map-Reduce isn’t the best match for all the problems. It’s good for simple elementary requests and problems that can be divided into independent units, but it’s not efficient for frequent analytic tasks.
- Entry-level programmers may find it difficult to be productive with Map-Reduce.
- Data Security is also an issue in Hadoop, though with new tools around like Kerberos authentication protocol is a great step forward in making Hadoop secure than before.
Conclusion
Hadoop has transformed into a huge system for distributed parallel processing of enormous amounts of data. Map-Reduce was the first way to use this OS (Operating System), but now there are other Apache open source projects like Spark, Hive, Pig, etc. to support development. Written in Java, Hadoop is able to run applications written in various programming languages like python, ruby and so on.
In a nutshell, Hadoop provides a dependable and scalable platform to store and analyze data.

















