
Apache Kafka is a fast and scalable messaging platform. Many companies use Kafka Architecture to enable communication between producers and consumers using messaging-based topics.
More than 33% of all Fortune 500 companies use Kafka.
The Kafka architecture is a set of APIs that enable Apache Kafka to be such a successful platform that powers tech giants like Twitter, Airbnb, Linkedin, and many others. This Redmonk graph shows the growth that Apache Kafka-related questions have seen on Github, which is a testament to its popularity.
What is Apache Kafka?
More and more companies are realizing that they have to build disruptive digital services, they need access to a wide stream of data which must be integrated. Moreover, traditional transactional data like orders, inventory and so on is now being complemented by more data.
This includes things such as page clicks, likes, searches, and recommendations. All this data can together provide insights into customer behaviour that can give companies an enormous competitive advantage. This is how Kafka proves useful.

Kafka was developed in 2010 at Linkedin. Linkedin was facing a problem of low latency ingestion of a large amount of data from the website into a lambda architecture which would be able to process events in real-time.
While real-time systems like traditional messaging queues (eg. ActiveMQ, RabbitMQ) support transactions, message consumption tracking and have great delivery rates, they were not appropriate for this use case. Without having input data, there is no point in building machine learning algorithms.
Linkedin needed something to get this input data from the source and move it around reliably. Kafka was developed as a solution to this problem.
In 2011, Linkedin made Kafka public. At this time, Kafka was ingesting more than 1 billion events a day. Since then, Kafka is being used by a number of companies to solve the problem of real-time processing. In fact, Kafka now has an ingestion rate of 1 trillion messages a day.
Why is Kafka used?
When it comes to Big Data there are two major concerns. The first challenge is to actually collect a large amount of data that is required, and the second is being able to analyze the data. A messaging system like Kafka can help overcome these challenges.
A messaging system transfers data from one application to another. This allows the applications to focus on the data without worrying about how to share it. For systems which have high throughput, Kafka works much better than traditional messaging systems.
It also has better partitioning, replication, and fault-tolerance which makes it a great fit for systems that process large-scale messages.
Kafka offers several benefits over messaging systems like ActiveMQ and RabbitMQ. These include:
- Reporting operational metrics based on the data it collects,
- Transforming all the source data into a standard format so that it can be used for in-depth analysis.
- Tracking activities on the website. It achieves this by storing and sending the events for real-time processes.
- Continuous processing of the streaming data and sending it to the topics.
- Higher reliability since Kafka is distributed, replicated, partitioned and has greater fault tolerance.
- Scaling up easily without requiring a lot of downtimes.
- Using a “Distributed commit log”. This means messages persist on the disk, making it durable.
- Keeping performance stable since it has high throughput for both publishing and subscribing messages.
The Use Cases for Kafka
Kafka has several different use cases. Some of these are mentioned below.
(i) Operational Metrics
Kafka aggregates the statistics from a number of distributed applications and then produces centralized feeds of operational data. This data can then be used by companies for further analysis or to monitor performance.
(ii) Log Aggregation Solution
Many organizations use Kafka to collect logs from a number of services and then make them available to consumers in a standard format.
(iii) Stream Processing
Stream processing is done by frameworks like Storm and Spart Streaming. They read data from a topic, process it, and then write the processed data to a new topic. The processed data is then available for users and applications. Since Kafka is very durable, it becomes very useful in effective stream processing.
Kafka Architecture Explained
The Kafka architecture is the foundation of Apache Kafka. It consists of four main APIs on which Kafka runs. Here is a Kafka architecture diagram.
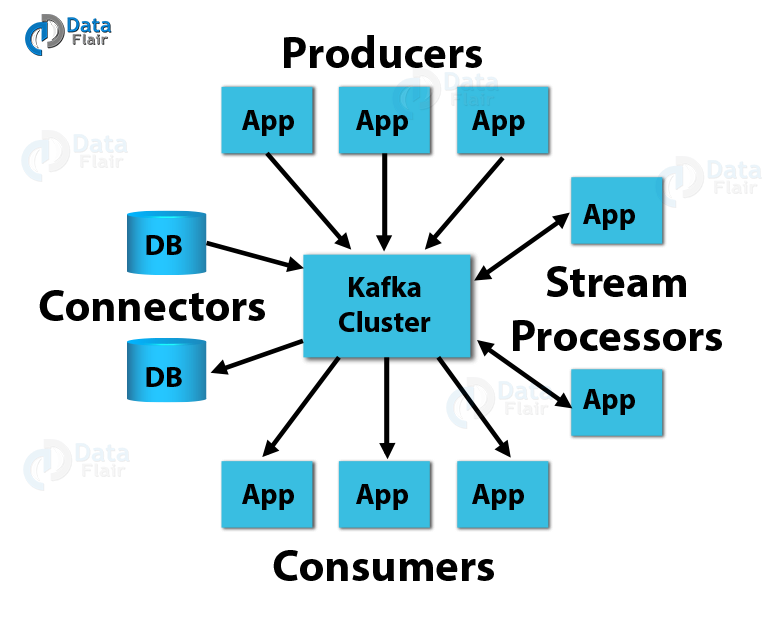
This Kafka architecture diagram shows the 4 main APIs that are used in Kafka. These are:
(i) Producer API
The Producer API allows an application to publish a stream of records to one or more Kafka topics.
(ii) Consumer API
This API allows an application to subscribe to one or more topics. It also allows the application to process the stream of records that are published to the topic(s).
(ii) Streams API
The streams API allows an application to act as a stream processor. The application consumes an input stream from one or more topics and produces an output stream to one or more output topics thereby transforming input streams to output streams.
(iv) Connector API
The connector API builds reusable producers and consumers that connect Kafka topics to applications and data systems.
Here is a video which explains the basics of Kafka architecture in some detail.
Kafka Cluster Architecture
The Kafka architecture can also be examined as a cluster with different components. Here is a cluster Kafka architecture diagram.
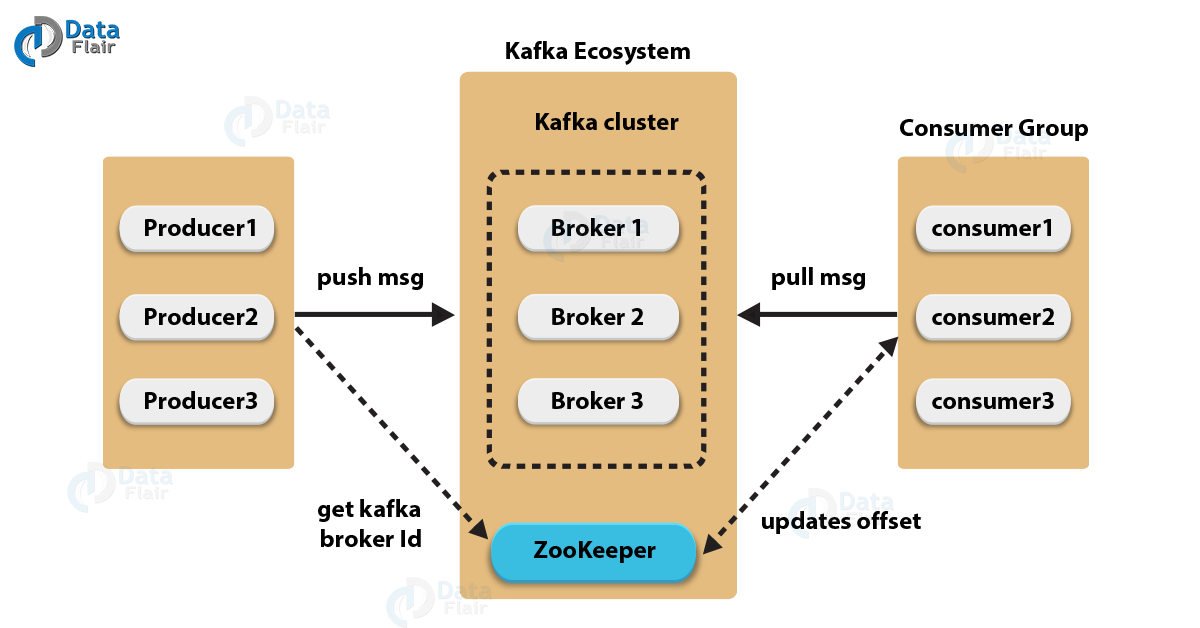
Here are the different components as described in the Kafka cluster architecture diagram.
(i) Kafka Broker
A Kafka cluster typically consists of many brokers. They maintain load balance for the cluster. One Kafka broker can handle thousands of reads and writes per second. However, since brokers are stateless they use Zookeeper to maintain the cluster state.
(ii) Kafka ZooKeeper
Kafka broker uses ZooKeeper to manage and coordinate. The ZooKeeper notifies the producers and consumers when a new broker enters the Kafka system or if a broker fails in the system. On being informed about the failure of a broker, the producer and consumer decide how to act and start coordinating with some other broker.
(iii) Kafka Producers
Producers in the Kafka cluster architecture push the data to brokers. The Kafka producer sends messages to the broker at a speed that the broker can handle. Therefore, it doesn’t wait for acknowledgments from the broker. Producers can also search for and send messages to new brokers exactly when they start.
(iv) Kafka Consumers
Since the Kafka brokers are stateless, Kafka consumers maintain the number of messages that have been consumed. They do this using the partition offset. The consumer acknowledges each message offset which is an assurance that it has consumed all the messages before it.
Some Fundamental Concepts Of Kafka Architecture
Here are some of the fundamental concepts that you should know about to have a complete idea of how Kafka architecture works.
(i) Kafka Topics
The topic is a logical channel. Producers publish messages to a topic and consumers receive a message from the topic. Messages in Kafka are structured. Therefore, a particular type of message is only published on a particular topic. In Kafka cluster architecture, a topic is identified by its name and is unique. There is no limit to the number of topics that can be present. However, as soon as the data is published to a topic, it cannot be changed or updated in any way.
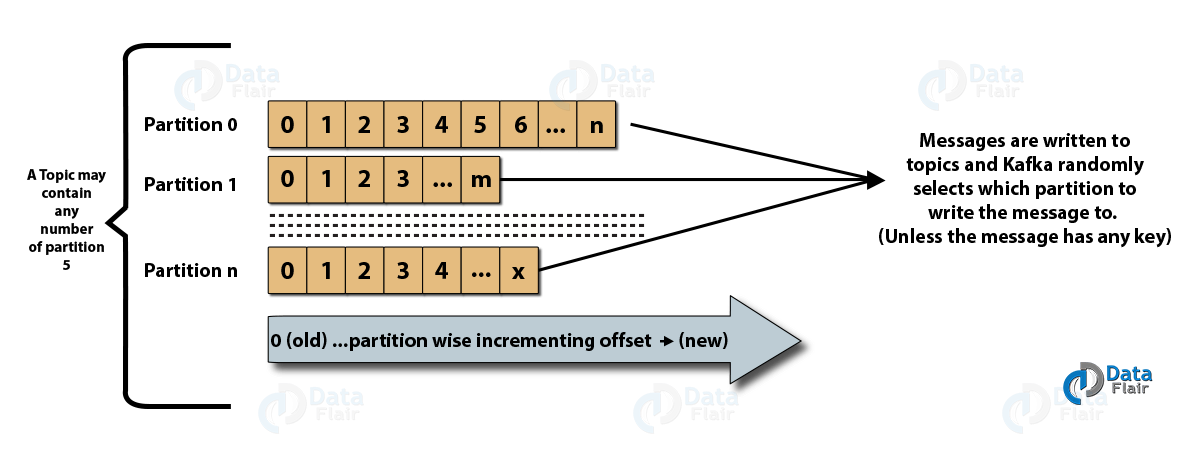
(ii) Partitions in Kafka
In a Kafka cluster, topics are split into what are known as partitions. However, there is no guarantee as to which partition a published message will be written; it happens completely at random.
However, in one partition, the messages are stored in a sequence. Like topics, there is no limit to the number of partitions that are possible. Within a partition, each message is assigned an incremental id which is also known as an offset.
Here is an image which depicts the relationship between topics and partitions.
(iii) Topic Replication Factor
Most Kafka systems factor in something known as topic replication. This helps to prevent a crisis if a broker fails. In such an event, the topics’ replicas from another broker can salvage the situation.
A topic replication factor of 2 means that a topic will have one additional copy in a different broker. This is of course apart from the primary topic. Of course, the replication factor cannot be more than the total number of brokers that are available.
Summing Up
Thousands of companies are built on Apache Kafka. Not just the tech unicorns, but more traditional enterprises are also looking at Kafka as a solution to their big data concerns. The top 10 travel companies, 7 of the top 10 banks, 8 of the top 10 insurance companies, and 9 out of the top 10 telecom companies all use Kafka.
In fact, just Linkedin, Microsoft and Netflix together process more than 1 trillion messages a day with Kafka. From real-time streams of data to big data collection to real-time analysis, Kafka has multiple uses. As a result, there is a high demand for professionals who have expertise in big data analytics using the Apache Kafka messaging system. Thus, you can easily start your journey to becoming a Data Scientist by having detailed a
Are you inspired by the opportunity of Data Science? Getting enrolled in Data Science Course will help you in building a career as a Data Scientist.

















