
Data Science is the study of data and a data scientist is someone who solves problems by studying data. So pretty much all science is Data Science. We observe, we make predictions, we test and we update our ideas. So if we were given a data set of meteorite landings over the past 10 years we could come up with questions that we think the data might help us solve like what area is most likely to get hit or how does atmospheric pressure affect meteorite trajectory.
Then we could write a little code that trains a machine learning model on that data and predicts the answer. We can use an existing model and there are a lot of them or build our own. Traditionally you would need a PhD for this stuff but with the world’s data doubling every two years and machine learning algorithms getting more powerful anyone can become a data scientist. You just need time and motivation.
If you have those two things you’ll be able to complete a bunch of data science projects and upload them to your GitHub. GitHub is the new resume. It’s not about how many degrees you have it’s about what you can do.

Why Python?
We’re picking Python for two reasons – it’s designed for readability and it is general purpose which uses a library called Sphinx (python data mining library) to read an audio file, convert it to text and print it out. That’s just five lines of code and we can still read what it’s doing since every word is descriptive and compact. Now let’s look at a similar app in C++ that’s about a hundred lines!

Setup Python Tool and Environment for Python Data Mining
To build our gender classification app there are four steps:
We’ll install Python –> Set up our environment –> Install our dependencies –> Write the Python script
Let’s start by installing Python. If you’re on a Mac or Linux machine Python comes pre-installed. If you’re on Windows, you’ll want to download the latest version of Python. On Mac you can download the installer package and go through the necessary steps to install it then you’ll be able to compile your scripts from the terminal using the Python keyword.
On Linux you can download the source then in terminal type in the commands to install it you’ll then be able to run Python scripts using the Python keyword. On Windows you can go and download the Installer and make sure ‘add Python DXE to path’ is set to be installed on your local hard drive and once it’s finished you can run Python right from command-line.
Now that we have Python installed let’s set up our environment. We can use any text editor (for example, sublime text). We can type our Python code in there and compile it with the terminal by pointing our Python interpreter to our script, that’s it.
We only need the terminal and our text editor to run our scripts. So we’ve got our environment set up. Let’s move on to installing our dependencies – dependencies are packages that our code depends on. We call them at the top of each script and write with the ‘import’ statement.
Any programmer can write a package to say figure out some complex problem in a thousand lines of code, upload it to the Python package server and we could download it and call it with a single line of code. All code is part of a greater whole, it’s all linked together in a grand chain of dependencies.
It’s like building a house in order for you to be able to build the roof of a house, it’d be nice if you already had the dependencies. The Python package manager ‘pip’ helps us install dependencies and we’ll use it right from command-line. You can install ‘pip’ for Python 3 using these commands for whichever operating system.
You’re using the only dependency we’ll be using in this data mining tutorial python to build our gender classifier,
pip install -U -scikit-learn
A machine learning package with a bunch of pre-built models for us to use we have our dependencies installed and now we’re ready to write our script.

Python Data Mining Classification Example – Male or Female?
In this post, we’re going to do a practical data mining with python project which is to set up our Python environment and write a 10 lines script that can classify anyone as male or female given just our body measurements.

How to write the Python Script, introducing Decision Trees
We’ll start by importing it first as we should for all the dependencies. We’re going to use a specific submodule of ‘-scikit-learn’ called tree that will let us build a machine learning model called a decision tree. A decision tree is like a flowchart that stores data. It asks each labeled data point it receives a yes-or-no question.
Does it contain X or not. if the answer is yes the data moves one direction. if the answer is no it moves in the other. it’ll build every node in the tree the more data points it receives. Then when we have a new unlabeled data point we can feed it to the tree. It’ll ask it a series of questions until it labels it. That label is our classification.
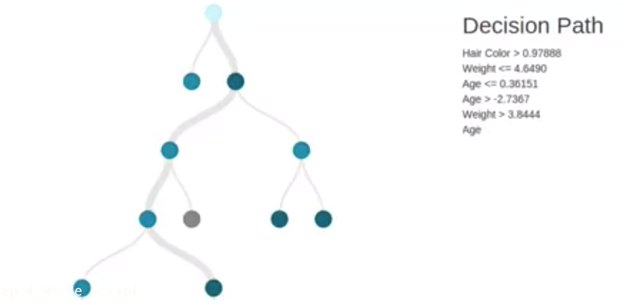
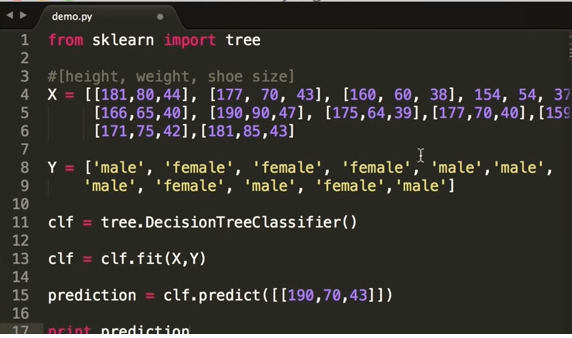
The more data we train it on the more accurate the classification. Let’s start by creating our dataset programmatically. We’ll write our first variable X as a list of lists a variable is a value that can change and we’ll store a list of lists in it. A list is a data type in Python that can store a sequence of values.
Here each value is a list itself that contains three numbers that represent the length, width, and shoe-size of a person. We’ll write off these so our data set size is only eleven people. We’ll write one more variable called Y to store a list of labels. Each label is a gender and is associated with a list of body metrics in the previous list.
We’ll write them as strings which is a data type used to represent text instead of numbers. Now that we have our data set we’ll want to define a variable to store our decision tree model. Let’s call it CLF – short for Classifier and it’ll store our decision tree classifier.
We can reference our tree dependency directly by calling it here and initialize the decision tree by calling the decision tree method on the tree object. now that we have our tree variable we can train it on our data set. We’ll call the fit method on the classifier variable which takes two arguments that will store our x and y variables as the arguments and the result will be stored in the updated CLF variable. The fit method trains the decision tree on our data set.
Result Model – Running the script
Let’s test it by classifying the gender of someone given a new list of body matrix. We’ll create a variable called prediction to store the result and call the ‘predict method’ of our decision tree to predict the gender given these three values in a list. Then we can print it out determine all via the print command. we can run the script in the terminal by saving it as ‘demo.py’ and running it via the Python ‘demo.py’ command.
Facebook Data Mining Python | Twitter Data Mining Python
Python script that uses Twitter and Facebook to understand how people are feeling about a topic that we choose using the natural language library. People ask various questions like how does Prime Minister Modi have so many supporters, we’ve invented the sciences of psychology and sociology to help us study these things. Both are the scientific study of people and all the emotion and relationships and behaviours that they display. Traditionally psychologists would formulate a hypothesis than to test it they would find a subset of people that fit their category bring them into the lab then ask them to do some tasks while recording the results. But with data freely available the data scientists can do the same thing with the best psychology tool out there – twitter and facebook.

Twitter and Facebook are a treasure chest repository of sentiments of people around the world, output thousands of reactions and opinions on every topic under the sun every second of every day. It’s like one big psychological database that’s constantly being updated and we can use it to analyze millions of tech snippets in seconds with the power of machine learning.
Takeaway
So to break it down, data scientists solve problems using data and because easy to use machine learning libraries and abundant data are now available everywhere you can become one. Python is a programming language for both beginners and experts and emphasizes readability and a decision tree is a model that classifies data by creating branches for every possible outcome.

—
Images, Intercepts and Concept Credits:
Siraj Raval – Director @ School of AI, A Youtube Star and the Bestselling Author. | https://twitter.com/sirajraval
P E X E L S – Beautiful free photos contributed by our talented community.

















