
Spark is an open-source application and is a supplement to Hadoop’s Big Data technology.
In the past five years, the interest in Hadoop has increased by 83%, according to a Google Trends report.
Apache Spark has over 500 contributions and a user base of over 225,000 members, making it the most in-demand framework across various industries.
Spark functions similar to MapReduce; it distributes data across clusters, and the clusters run in parallel.
The Spark architecture is a master/slave architecture, where the driver is the central coordinator of all Spark executions.
Before we dive into the Spark Architecture, let’s understand what Apache Spark is.
What is Apache Spark?
Apache Spark is an open-source computing framework that is used for analytics, graph processing, and machine learning. Spark is used for Scala, Python, R, Java, and SQL programming languages.
But, what is Apache Spark used for? Spark has a real-time processing framework that processes loads of data every day. Spark is used not just in IT companies but across various industries like healthcare, banking, stock exchanges, and more.
The primary reason for its popularity is that Spark architecture is well-layered and integrated with other libraries, making it easier to use. It is a master/slave architecture and has two main daemons: the master daemon and the worker daemon.
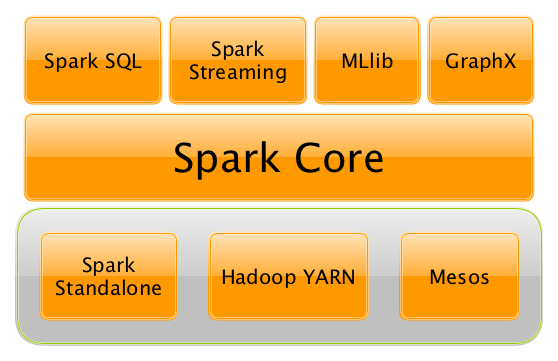
The two important aspects of a Spark architecture are the Spark ecosystem and RDD.
An Apache Spark ecosystem contains Spark SQL, Scala, MLib, and the core Spark component.
Spark Core is the base for all parallel data processing, and the libraries build on the core, including SQL and machine learning, allow for processing a diverse workload. Spark includes various libraries and provides quality support for R, Scala, Java, etc.
Spark SQL is a simple transition for users familiar with other Big Data tools, especially RDBMS.
RDD, or Resilient Distributed Dataset, is considered the building block of a Spark application. The data in an RDD is divided into chunks, and it is immutable. RDDs can perform transformations and actions.
Features of the Apache Spark Architecture
Spark has a large community and a variety of libraries. It provides an interface for clusters, which also have built-in parallelism and are fault-tolerant. Here are some top features of Apache Spark architecture.
Speed
Compared to Hadoop MapReduce, Spark batch processing is 100 times faster. This is because Spark employs controlled partitioning to manage data by dividing it into partitions, so data can be distributed parallel to minimize network traffic.
Polyglot
Polyglot is used for high-level APIs in R, Python, Java, and Scala, meaning that coding is possible in any of these four languages. It also enables shell in Scala using the installed directory ./bin/spark-shell and in Python using the installed directory ./bin/pyspark.
Real-Time Computation
The Spark architecture boasts in-memory computation, making it low-latency. Spark is designed for high scalability, and the Spark clusters can run on systems with thousands of nodes. And it also supports many computational methods.
Hadoop Integration
Spark is relatively new, and most Big Data engineers started their career with Hadoop, and Spark’s compatibility with Hadoop is a huge bonus. While Spark replaces the MapReduce function of Hadoop, it can still run at the top of the Hadoop cluster using YARN for scheduling resources.
Machine Learning
MLib, the machine learning feature of Spark is very useful for data processing since it eliminates the use of other tools. This gives data engineers a unified engine that’s easy to operate.
Slower Evaluation
The reason Spark has more speed than other data processing systems is that it puts off evaluation until it becomes essential. Spark adds transformations to a Directed Acyclic Graph for computation, and only after the driver requests the data will the DAG be executed.
What are the Spark Terminologies?
The following are all the terminologies used in the Spark architecture.
Spark Context
Apache SparkContext is an essential part of the Spark framework. It is used to create RDDs, access Spark Services, run jobs, and broadcast variables. It also helps establish a connection with the Spark execution environment, which acts as the master of Spark application.
With SparkContext, users can the current status of the Spark application, cancel the job or stage, and run the job synchronously or asynchronously.
Spark Shell
Spark Shell is a Spark application that is written in Scala. It helps users familiarize themselves with Spark features and helps develop standalone Spark application. Spark Shell has a command-line operation with auto-completion.
Spark Shell is the primary reason Spark can process data sets of all sizes.
Spark Application
The Spark computation is a computation application that works on the user-supplied code to process a result. Spark application processes can run in the background even when it’s not being used to run a job.
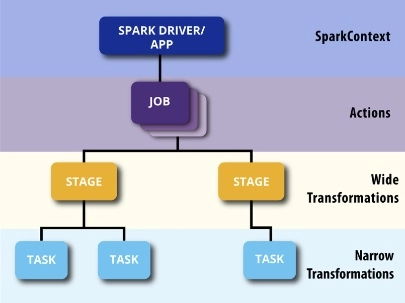
Job
A job is a parallel computation containing all the tasks that arise in response to Spark actions.
Stage
Every job in Spark is divided into small parts called stages. These stages are known as computational boundaries, and all the stages rely on each other. No computation can be done in a single stage and requires multiple stages to complete.
Task
A task is a set of work that is sent to the executioner. There is a task for every stage, with each partition having one task.
Understanding Spark Architecture
Spark architecture is well-layered, and all the Spark components and layers are loosely coupled in the architecture. The further extensions in Spark are its extensions and libraries.
The Spark architecture has two basic components: RDD and DAG.
RDD (Resilient Distributed Dataset)
RDD stands for:
Resilient: It’s fault-tolerant and can build data in case of a failure
Distributed: The data is distributed among multiple nodes in a cluster
Dataset: Data is partitioned based on values
RDD is immutable, meaning that it cannot be modified once created, but it can be transformed at any time. Every Dataset in RDD is divided into multiple logical partitions, and this distribution is done by Spark, so users don’t have to worry about computing the right distribution.
An RDD can be created by existing parallelizing collections in your driver programs or using a dataset in an external system, like HBase or HDFS. RDDs allow you to perform two types of applications:
Transformations
Transformation is the application applied to create a new RDD.
Actions
Actions are applied on an RDD, which instructs Spark to apply computation and sent the result to the driver.
DAG (Directed Acyclic Graph)
The DAG in Spark supports cyclic data flow. Every Spark job creates a DAG of task stages that will be executed on the cluster.
Spark DAGs can contain many stages, unlike the Hadoop MapReduce which has only two predefined stages.
In a Spark DAG, there are consecutive computation stages that optimize the execution plan.
Spark DAG uses the Scala interpreter to interpret codes with the same modifications. When this code is entered in a Spark console, an operator graph is created.
The DAG then divides the operators into stages in the DAG scheduler. The stages are passed to the Task scheduler, which is then launched through the Cluster manager.
You can achieve fault-tolerance in Spark with DAG.
RDD splits data into a partition, and every node operates on a partition. The composition of these operations together and the Spark execution engine views this as DAG.
When a node crashes in the middle of an operation, the cluster manages to find out the dead node and assigns another node to the process. This will prevent any data loss.
To optimize DAG, you can rearrange or combine operators as per your requirement.
Let’s understand the architecture in detail with these steps:
(i) When the client sends the Spark application code, the driver automatically converts the code containing transformations and actions into a logical DAG. This is also when pipeline transformations and other optimizations are performed.
(ii) The next part is converting the DAG into a physical execution plan with multiple stages. Once that’s done, it creates physical execution units known as tasks. These tasks are sent to the cluster.
(iii) Lastly, the driver and the cluster manager organize the resources. The driver then sends tasks to the executor based on data placement. This enables the driver to have a complete view of executors executing the task.
The driver monitors the entire execution process of tasks. They also schedule future tasks based on data placement.
Working of Spark Architecture
Let us look a bit deeper into the working of Spark architecture.
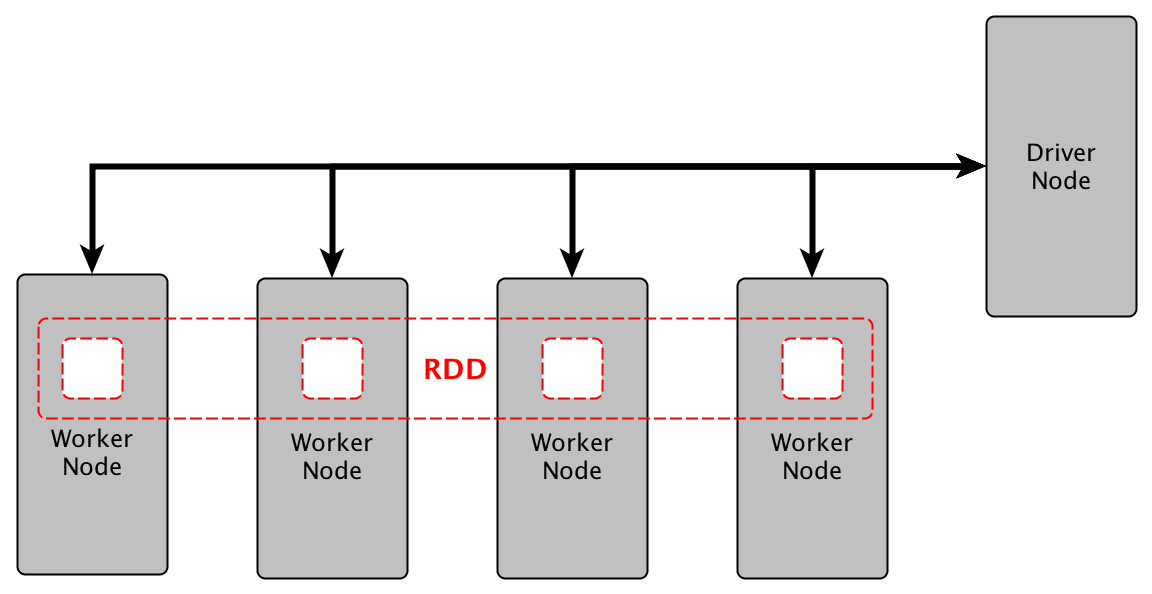
The master node has the driver program that is responsible for your Spark application. In Spark, your code is the driver program, while in an interactive shell, then the shell acts as the driver. Within the master node, you should create a SparkContext, which can act as a gateway to other Spark functionalities.
This is just like a database connection, and all your commands executed in the database go through the database collection. The same applies to SparkContext, where all you do in Spark goes through SparkContext.
The SparkContext works with the cluster manager, helping it to manage various jobs. The SparkContext and cluster work together to execute a job. Every job is divided into various parts that are distributed over the worker node.
Worker nodes are slaves whose task is to execute a task. These tasks are then sent to the partitioned RDDs to be executed, and the results are returned to the SparkContext. When users increase the number of workers, the jobs can be divided into more partitions to make execution faster.
Watch this Spark architecture video to understand the working mechanism of Spark better.
Components of Spark Run-time Architecture
Spark architecture has various run-time components. Let’s look at each of them in detail.
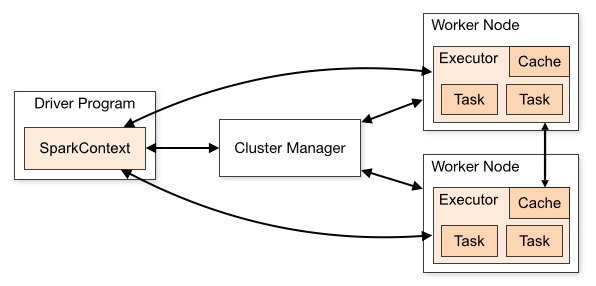
Spark Driver
The main Spark computation method runs in the Spark driver. The driver is responsible for creating user codes to create RDDs and SparkContext. When the user launches a Spark Shell, the Spark driver is created. A Spark application is complete when the driver is terminated.
A Spark driver splits the Spark application tasks that are scheduled to be run on the executor. The driver has two primary functions: to convert a user program into the task and to schedule a task on the executor.
Cluster Manager
Cluster managers are used to launching executors and even drivers. Jobs and actions are schedules on the cluster manager using Spark Scheduler like FIFO.
Cluster manager is a pluggable component of Spark, and its applications can be dynamically adjusted depending on the workload. This enables the application to use free resources, which can be requested again when there is a demand. This feature is available on all cluster managers.
Executors
The individual tasks in a Spark job run on the Spark executor. An executor is launched only once at the start of the application, and it keeps running throughout the life of the application.
Executors do not hinder the working of a Spark application, and even if an executor fails. The executor is used to run the task that makes up the application and returns the result to the driver. It also provides storage in its memory for RDDs cached by users.
Here’s a Spark architecture diagram that shows the functioning of the run-time components. When working with cluster concepts, you need to know the right Spark applications and what those applications mean.
Conclusion
Spa4k helps users break down high computational jobs into smaller, more precise tasks that are executed by worker nodes.
In addition, go through Spark Interview Questions for being better prepared for a career in Apache Spark.
Spark is a low latency computation application and can process data interactively. This feature makes Spark the preferred application over Hadoop.
If you want to build a career in Data Science, enroll in the Data Science Course today.


















Thanks for the this good information
This blog was really awesome. Thank you.