Ever since computers were invented, we have wondered whether they might be made to learn. If we could understand how to program them to learn-to improve automatically with experience-the impact would be dramatic. Let’s learn the supervised and unsupervised learning in Data Mining.
A successful understanding of how to make computers learn would open up many new uses of computers and new levels of competence and customization. And a detailed understanding of information processing algorithms for machine learning might lead to a better understanding of human learning abilities and disabilities as well.
“The key to artificial intelligence has always been the representation.” — Jeff Hawkins
Students venturing in machine learning have been experiencing difficulties in differentiating supervised learning from unsupervised learning. It appears that the procedure used in both learning methods is the same, which makes it difficult for one to differentiate between the two methods of learning. However, upon scrutiny and unwavering attention, one can clearly understand that there exist significant differences between supervised and unsupervised learning in data mining.
Why AI/ML?
The future of planet Earth is Artificial Intelligence / Machine Learning. Anyone who does not understand it will soon find themselves left behind. Waking up in this world full of innovation feels more and more like magic. There are many kinds of implementations and techniques to carry out Artificial Intelligence and Machine Learning to solve real-time problems, out of which Supervised Learning is one of the most used approaches.
Machine learning uses two types of techniques: supervised learning, which trains a model on known input and output data so that it can predict future outputs, and unsupervised learning, which finds hidden patterns or intrinsic structures in input data.
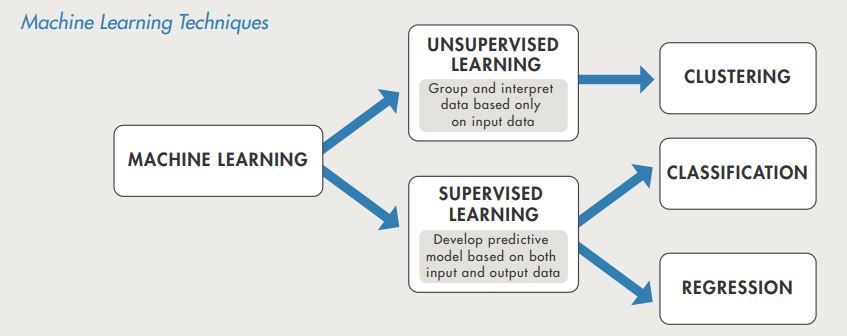
[Image from www.mathworks.com]
What is Supervised Learning?
Supervised methods are methods that attempt to discover the relationship between input attributes (sometimes called independent variables) and a target attribute (sometimes referred to as a dependent variable). The relationship discovered is represented in a structure referred to as a model.
Usually, models describe and explain phenomena, which are hidden in the dataset and can be used for predicting the value of the target attribute knowing the values of the input attributes. The supervised methods can be implemented in a variety of domains such as marketing, finance, and manufacturing.
It is useful to distinguish between two main supervised models: classification models (classifiers) and Regression Models. Regression models map the input space into a real-value domain.
For instance, a regressor can predict the demand for a certain product given its characteristics. On the other hand, classifiers map the input space into pre-defined classes. For instance, classifiers can be used to classify mortgage consumers as good (fully pay back the mortgage on time) and bad (delayed payback).
There are many alternatives for representing classifiers, for example, support vector machines, decision trees, probabilistic summaries, algebraic function, etc. Along with regression and probability estimation, classification is one of the most studied models, possibly one with the greatest practical relevance. The potential benefits of progress in classification are immense since the technique has a great impact on other areas, both within Data Mining and in its applications.
Classification
Classification deals with assigning observations into discrete categories, rather than estimating continuous quantities. In the simplest case, there are two possible categories; this case is known as binary classification. Many important questions can be framed in terms of binary classification. Will a given customer leave us for a competitor?
Does a given patient have cancer? Does a given image contain a hot dog? Algorithms for performing binary classification are particularly important because many of the algorithms for performing the more general kind of classification where there are arbitrary labels are simply a bunch of binary classifiers working together.
For instance, a simple solution to the handwriting recognition problem is to simply train a bunch of binary classifiers: a 0-detector, a 1-detector, a 2-detector, and so on, which output their certainty that the image is of their respective digit. The classifier just outputs the digit whose classifier has the highest certainty.
Some of the most used classification algorithms
- K—Nearest Neighbor
- Decision Trees
- Naive Bayes
- Support Vector Machines
In the learning step, the classification model builds the classifier by analyzing the training set. In the classification step, the class labels for given data are predicted. The dataset tuples and their associated class labels under analysis are split into a training set and test set.
The individual tuples that make up the training set are randomly sampled from the dataset under analysis. The remaining tuples form the test set and are independent of the training tuples, meaning that they will not be used to build the classifier.
The test set is used to estimate the predictive accuracy of a classifier. The accuracy of a classifier is the percentage of test tuples that are correctly classified by the classifier. To achieve higher accuracy, the best way is to test out different algorithms and trying different parameters within each algorithm as well. The best one can be selected by cross-validation.
To choose a good algorithm for a problem, parameters such as accuracy, training time, linearity, number of parameters and special cases must be taken into consideration for different algorithms.
K-Nearest Neighbors:
An algorithm is said to be a Lazy Learner if it simply stores the tuples of the training set and waits until the test tuple is given. Only when it sees the test tuple does it perform generalization to classify the tuple based on its similarity to the stored training tuples.K -Nearest Neighbor Classifier is a lazy learner.
KNN is based on learning by analogy, that is, by comparing a given test tuple with training tuples that are similar to it. The training tuples are described by n attributes. Each tuple represents a point in an n-dimensional space. In this way, all training tuples are stored in n-dimensional pattern space.
When given an unknown tuple, a k-nearest neighbor classifier searches the pattern space for the k training tuples that are closest to the unknown tuple. These k training tuples are the k “nearest neighbors” of the unknown tuple. “Closeness” is defined regarding a distance metric, such as Euclidean distance. A good value for K is determined experimentally.
Regression
Regression is usually termed as determining relationships between two or more variables. For example consider you have to predict the income of a person, based on the given input data X.
Here, the target variable means the unknown variable we care about predicting, and continuous means there aren’t gaps(discontinuities) in the value that Y can take on.
Predicting income is a classic regression problem. Your input data should have all the information (known as features) about the individual that can predict income such as his working hours, education experience, job title, a place he lives.
Some of the commonly used Regression models are :
- Linear Regression
- Logistic Regression
- Polynomial Regression
Linear Regression establishes a relationship between the dependent variable (Y) and one or more independent variables (X) using a best fit straight line (also known as regression line).
Mathematically,
h(xi) = βo + β1 * xi + e
where βo is the intercept, β1 is the slope of the line and e is error term.
Logistic Regression is an algorithm, that is used where the response variable is categorical. The idea of Logistic Regression is to find a relationship between features and probability of a particular outcome.
Mathematically,
p(X) = βo + β1 * X Where p(x) = p(y = 1 | x)
Polynomial Regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x.
Difference between Supervised and Unsupervised Learning
The difference is that in supervised learning the “categories”, “classes” or “labels” are known. In unsupervised learning, they are not, and the learning process attempts to find appropriate “categories”. In both kinds of learning all parameters are considered to determine which are most appropriate to perform the classification.
Whether you chose supervised or unsupervised should be based on whether or not you know what the “categories” of your data are. If you know, use supervised learning. If you do not know, then use unsupervised.
Table Showing Differences Between Supervised Learning and Unsupervised Learning: Comparison Chart
| Supervised Learning | Unsupervised Learning | |
| Input Data | Uses Known and Labeled Input Data | Uses Unknown Input Data |
| Computational Complexity | Very Complex in Computation | Less Computational Complexity |
| Real Time | Uses off-line analysis | Uses Real Time Analysis of Data |
| Number of Classes | Number of Classes is Known | Number of Classes is not Known |
| Accuracy of Results | Accurate and Reliable Results | Moderate Accurate and Reliable Results |
Summary
- Data mining is becoming an essential aspect in the current business world due to increased raw data that organizations need to analyze and process so that they can make sound and reliable decisions.
- This explains why the need for machine learning is growing and thus requiring people with sufficient knowledge of both supervised machine learning and unsupervised machine learning.
- It is worth understanding that each method of learning offers its own advantages and disadvantages. This means that one has to be conversant with both methods of machine learning before determine which method one will use to analyze data.
Reference
- https://www.cs.huji.ac.il/~shais/UnderstandingMachineLearning/understanding-machine-learning-theory-algorithms.pdf
- https://towardsdatascience.com