
In this article, we shall examine what text classification is and understand its significance.
We live in a fast-paced age where no one has time to read an entire message. Usually, one glances through emails and other communication to get the gist of the matter. It can be challenging to capture the central idea of a paragraph by just glancing through it.
IBM estimates that nearly 80% of all information is unstructured, with the text being the most common form of unstructured data. Analyzing and understanding the text is essential for extracting value out of it. Text classification can come to your rescue in such circumstances.
What is Text Classification?
Text classification can be defined as the process of assigning categories or tags to text depending on its content. It has wide applications in Natural Language Processing such as topic labeling, intent detection, spam detection, and sentiment analysis.
Today, people communicate through emails. As it is possible to access emails from anywhere, it becomes easy for the sender to classify the text in such a manner that it becomes easy for the reader to get the message quickly.
Want to Know the Path to Become a Data Science Expert?Download Detailed Brochure and Get Complimentary access to Live Online Demo Class with Industry Expert.
Date: April 27 (Sat) | 11 AM - 12 PM (IST)
Download Detailed Brochure and Get Complimentary access to Live Online Demo Class with Industry Expert.
Importance of Text Classification
You have unstructured data in the form of text all over the place. Some of the best examples are product reviews, emails, chats, social media interactions, survey responses, webpages, and so on. However, it becomes a challenge to extract insights from unstructured text. One has to go through the entire communication to understand what it is all about. Text classification can be beneficial to make the reader understand the content better.
By using classifiers, companies can structure business communications like emails, webpages, and social media messages quickly. Thus, companies end up saving a lot of time.

What is Text Classification, and How Does It Work? Let us now see how it works. We shall also discuss text classification algorithms and text classification machine learning systems. Finally, we shall go through some of the typical business applications of text classification.
An Example of Text Classification
Let us look at the following sentence and try to grab the central idea. It is one of the most common examples of text classifications.
This particular user interface is not only straightforward but also easy to use.
If you analyze this sentence, nothing seems wrong with it. However, it does appear a bit long to explain something that can be expressed in a few words. A text classifier will go through the sentence to capture the essence. It becomes easy when you assign tags like UI and easy to use. By highlighting these words, we can say that “UI is easy to use.” It makes it simple for the reader to understand the point.
How Does Text Classification Work?
There are two ways of classifying text – manual and automatic. The former methodology involves a human annotator to go through the content of the text and categorize it accordingly. It is a time-consuming process but extremely effective all the same. It can produce high-quality results but can be expensive. The only drawback is that there can be an element of human error in this type of text classification.
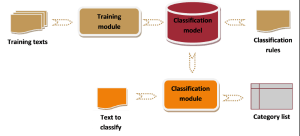
The latter method uses machine learning and natural language processing among other techniques for classifying text quickly. At the same time, the process is cost-effective. However, there are drawbacks because the machines could misinterpret specific words and classify them incorrectly, thereby sending the wrong message altogether.
Automatic text classification involves three different types of systems:
1. Text Classification based on rules
2. Text Classification Machine Learning
3. Hybrid systems
Rule-Based Text Classification
This system uses handcrafted linguistic rules to classify text. These rules help the system to use relevant elements of a text for identifying the categories based on the content. Each rule consists of a pattern and a predicted group.

This example will make things clear to you.
Let us assume you want to classify news articles into two different groups like politics and sports. Naturally, you will have to define words that characterize each group. For example, the terms related to sports can be cricket, badminton, football, Pele, Tendulkar, and so on. Similarly, you can use words like Prime Minister, cabinet, Parliament, Act, elections, and other similar words to classify news.
When you classify a new text, the system counts the number of politics-related words or news-related words separately. If the sports-related terms are more in number, it classifies the news as sports news. Similar is the case for political news.
For example, if the news headline says, “Sachin Tendulkar is the best cricket player India has ever produced,” the system can identify it as sports news immediately. Similarly, the news headline, “The Parliament passed the Citizenship Amendment Act today with a clear majority,” qualifies as a political news item.
This system is an effective one. However, there can be a news item like, “Sachin Tendulkar spoke for the first time in the Parliament today” or “The Prime Minister went to watch a cricket match today.” Such a news headline can pose problems for the automatic text classification systems. It will not know how to classify such news. Therefore, manual text classification comes handy in such circumstances.
Secondly, it can be a time-consuming exercise to generate rules for a complex system. It will require a great deal of analyzing and testing. Such a system can be a challenge to maintain because new rules can affect the results of pre-existing regulations, as well.
Text Classification Machine Learning
Text Classification Machine Learning systems do not rely on manually crafted rules. On the other hand, it learns to classify text based on past observations. It uses pre-labeled examples as training data. Text Classification algorithms can learn the different associations between pieces of text and the output expected for a particular text or input.
Feature extraction is the first step towards training a classifier with machine learning. It is a method by which the machine transforms each text into a numerical representation in the vector form. The most common approach is a ‘bag of words,’ where a vector represents the frequency of a particular word in a predefined dictionary of words.
Thus, if we have a dictionary with the following words (cricket, this, is, match, on, superb, today, the, a, now), and we wish to vectorize the text, ‘A cricket match is on today,’ we have the following vector representation (1,0,0,1,1,0,1,0,1,0).
Similarly, the text classification machine learning algorithm is fed with such data that contains pairs of feature sets and tags for producing a classification model. It takes time before the text classification machine learning model begins to make accurate predictions. However, with sufficient training samples, it will be able to do so.
Text classification-using machines are any day more accurate than human-crafted rules, especially when the task is highly complicated. One can always keep on adding new examples to enable the system to learn new tasks.
Text Classification Algorithms
What is a text classification algorithm? We shall now see some of the text classification algorithms like Naïve Bayes family, deep learning, and support vector machines.
1. Naïve Bayes Family
One of the best families of statistical algorithms that we use when doing text classification is Naïve Bayes. The advantage is that one can get accurate results when the data is not much, and there are scarce computational resources.
The Naïve Bayes algorithm works on the Bayes Theorem that helps to compute the conditional probabilities of the occurrence of two events based on the likelihood of the occurrence of each event.
2. Support Vector Machines
Support Vector Mechanism is similar to Naïve Bayes algorithms because it does not require much training data to start producing accurate results. Compared to Naïve Bayes text classification algorithms, SVM requires more computational resources. At the same time, SVM produces much more accurate results in comparison to Naïve Bayes.
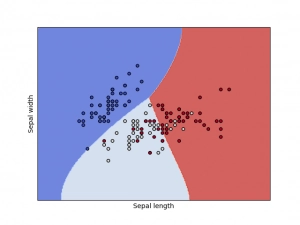
To put it simply, SVM draws a line or a hyperplane to divide space into two subspaces. One portion contains the vectors that belong to a group and the other includes vectors that do not belong to it.
3. Deep Learning
Deep learning is a set of text classification algorithms inspired by how the human brain works. Deep learning has the potential to reach high accuracy levels with minimal engineered features. Two common deep learning architectures used in text classification are Recurrent Neural Networks and Convolutional Neural Networks.
The disadvantage of SVM and NB text classification algorithms is that they stagnate after reaching a specific threshold. Adding more data does not make them more accurate. On the other hand, deep learning gets better with as much additional data as possible. However, the demerit of deep learning is that it requires much more training data than traditional machine learning algorithms.
Some of the best deep learning algorithms are Word2Vec and GloVe.
4. Hybrid Systems
As the name suggests, Hybrid Systems are a combination of the rule-based system and the machine learning system. The best aspect of a hybrid system is that it is possible to fine-tune them by adding specific rules for the conflicting tags that have not been identified correctly.
How to Evaluate the Performance of a Text Classifier?
The best method to do so is Cross-Validation. This method involves splitting the training dataset into an equal length set of samples. For every set, train the text classifier with the remaining samples. Text classifiers make predictions on their respective sets following which the results are compared against the human-annotated tags. It enables you to find out when the forecast was right and when it made a mistake.
Using these results, it is possible to build performance metrics to assess how well a classifier works. Text classifiers have great significance in today’s times.
Why do Companies Use Text Classification with Machine Learning?
It is useful for the following reasons.
1. Scalability
It can be a challenge to analyze and organize data manually. The personal approach requires the classifier going through every piece of text carefully to understand and decide how to structure it. Machine learning makes it easy to analyze millions of documents at tremendous speed and a fraction of a cost.
2. Real-time analysis
Text classification machine learning algorithms can tackle critical situations immediately and take instant action. They can make accurate real-time predictions, thereby enabling companies to act instantly.
3. Consistency
Text classification algorithms eliminate human error. Human error can creep in due to distractions, fatigue, and boredom. Such errors can multiply and cause other mistakes. Machine learning is the ideal solution because it applies the same criteria to all data, thereby ensuring a great deal of consistency.
Applications of Text Classification
Text Classification has various applications such as classifying short texts or organizing large documents. Some of the best examples of text classification include language detection, sentiment analysis, intent detection, and topic labeling.
1. Language Detection
This text classification application classifies incoming text according to its language. It is useful for routing purposes to direct support tickets depending on their language to the appropriate team.
2. Sentiment Analysis
It is an automated process that determines whether the text is positive, negative, or neutral. It is useful in the field of product analytics, customer support, brand monitoring, and other similar activities.
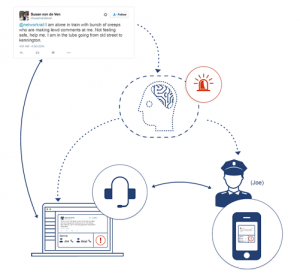
3. Intent Detection
Companies use this text classification method for detecting the customer’s intention. It is possible to train the text classifier to identify words like ‘Unsubscribe, Not Interested, Email Bounce, Wrong Person’, and so on in outbound sales emails.
4. Topic Labeling
Topic labeling is a crucial text classifier, as it helps understand what a given text wants to convey. It is useful for structuring and organizing data depending on the subject.
Other significant uses of text classification are brand monitoring, the voice of customers, social media monitoring, and customer service. Text classification is also useful in our daily interactive activities like spam filtering, and so on. Text classification can help organize business information and build cutting-edge systems. It ensures to convert your text data into quantitative data and thereby, helpful in getting actionable insights to drive business decisions. Text classifications help automate manual and repetitive tasks and help businesses perform better.
Conclusion
Are you inspired by the opportunity of Machine Learning? You may also enroll in Digital Vidya’s Machine Learning Course for more lucrative career options.
We hope you’ve enjoyed this article and for any further suggestions or queries, feel free to comment below.

















