
If you ever watched the popular game show Kaun Banega Crorepati, you would be familiar with the audience poll – one of the lifelines available to contestants when faced with doubt. This particular option, if you have observed carefully, turns out to be the most reliable, as the audience almost always polls correctly. The same idea applies to Ensemble Learning, which makes use of multiple ‘weak’ models so that the final collective model is quite accurate.
What Is an Ensemble Method?
There is strength in unity – and that ‘unity’ forms the basis of ensemble learning methods that combine multiple ‘weak’ models to produce a much more powerful model. In more technical terms, the ensemble method can be explained as a machine learning concept in which multiple models (weak learners) are trained using the same learning algorithm to solve the same problem for better results.
As you may already know, noise, bias, and variance are the leading causes of error in learning, and ensemble helps in minimising these factors by decreasing variance due to the combination of multiple classifiers. Bagging and boosting are standard ensemble methods that we will learn about in this article.
Weak Learners and Ensemble
A ‘weak learner’ is defined as a machine-learning algorithm that is only slightly more accurate than random guessing. Such algorithms are mostly quite basic in nature but find good use in ensemble learning that aggregates the weak learners to create a robust model.
Two things must be kept in mind:
For setting up an ensemble learning method, we generally use a single base learning algorithm to have homogeneous weak learners that are trained differently.
The weak learners that are selected must be in line with the aggregation method – for example, if we choose a base model with low bias and high variance, the aggregating method should be one that tends to reduce variance and vice versa.
But this leads to the next logical question – what are the major kinds of aggregation methods used for combining weak learners?
In the following few sections, we will focus on two major ensemble or aggregation methods for weak learners, namely, bagging and boosting.
Bagging and Boosting in Data Mining
Bagging and boosting are two types of ensemble methods that are used to decrease the variance of a single estimate by combining several estimates from multiple machine learning models. The aim of both bagging and boosting is to improve the accuracy and stability of machine learning algorithms through the aggregation of numerous ‘weak learners’ to create a ‘strong learner.’
What is Bagging?
Before we dive into bagging as an ensemble method, let’s first look at an essential foundational technique – bootstrap.
Bootstrap is a statistical method that is used for estimating a quantity from a data sample. For example, assume that we have a sample of 1000 values (x) and want to calculate the mean of the sample.
This can be calculated directly as:
mean(x) = 1/1000 * sum(x)
However, as the sample is small, there is a scope of error in the mean. To improve this estimate, we can use the bootstrap method. Here, we will create several (say about 1000) random sub-samples from the dataset with replacement and calculate the mean of each sub-sample. Next, we calculate the average of all the collected means, and this value may be used as the mean for the data.
Now we will talk about bagging, which is nothing but short for Bootstrap Aggregation. Bagging is a simple yet powerful ensemble method that is useful for reducing the variance in algorithms with high variance and low bias, such as classification models in the decision tree.
Such algorithms are intrinsically dependent on the data on which they are trained. This means that if the training data of a decision tree is changed, the resulting decision tree may turn out to be quite different. Bagging primarily applies the bootstrap method to the decision tree or high-variance machine learning algorithms.
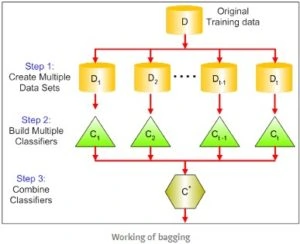
The process of bagging involves three main steps:
Creating multiple datasets or sub-sets from the original dataset using replacement
The same classifier is built on every data set (the subsets created above)
The predictions from all the classifiers are merged to give a stronger classifier, which, ideally, should have minimal variance.
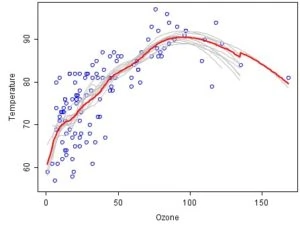
Here’s an example of bagging (from Wikipedia) that analyses the relationship between ozone and temperature.
In this data set, the relationship between temperature and ozone is apparently non-linear, based on the scatter plot. Now, 100 bootstrap samples of the data were drawn to make sure that each sample is different from the original data set, yet resembles it in distribution and variability. For each bootstrap sample, a LOESS smoother was fit. Now, predictions were made from these 100 smoothers across all 100 samples. You can see the first 10 predicted smooth fits as grey lines in the figure below. Notice the wiggly lines that clearly overfit the data, owing to a small bandwidth. Finally, the average of 100 smoothers, each fitted to a subset of the original data set, was taken to arrive at one bagged predictor (red line) or the mean, which is more stable and shows lesser overfit.
The Random Forest Approach to Bagging
Learning trees are popular base models for ensemble learning. Multiple trees put together to compose strong learners are also called “forest.” The leaning trees that are chosen to produce a forest can be of two types – shallow, with a few depths, or deep, with a lot of depths.
There are mainly two types of ensemble learning, bagging and boosting, used with deep trees and shallow trees, respectively. Shallow trees are known to have lesser variance but higher bias. This makes them a better choice for sequential methods, such as boosting, which will be described later. On the other hand, deep trees have low bias but higher variance, making them relevant for the bagging method, which is mainly used for reducing variance.
Random forest is also a bagging method that is aimed at reducing variance. The technique uses deep trees with bootstrapped samples that are combined together for a result with minimal variance. The critical difference between bagging and random forest is that random forests use multiple fitted trees that are less correlated with each other. This is achieved by not only sampling over observations in the dataset but also features, and keeping random subsets to build the tree.
Here’s an interesting video to understand this concept better:
What is Boosting?
Let’s answer a question before we start discussing what is boosting.
Do you think, if the first model incorrectly predicts a data point, combining the predictions will produce better results?
The answer is yes, especially in the case of boosting, which can be described as a sequential process wherein each subsequent model builds on the previous model to correct its flaws.
In simpler terms, boosting can be understood as a group of algorithms that make use of weighted averages to convert weak learners into strong learners. The difference between bagging and boosting is that, unlike bagging, where each model runs independently, and the output is aggregated in the end, boosting is all about working together, wherein each succeeding model is dependent on the previous one.
Also, while both bagging and boosting use bootstrapping, boosting weighs every sample in the data, meaning some samples may run more than others.
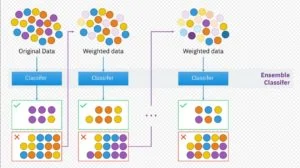
Steps involved in the boosting method:
Take all the distributions and assign equal weight to every observation.
In case there is any prediction error due to the first base learning algorithm, pay closer attention to the observations with prediction error.
Apply the next algorithm.
Repeat the above two steps in their respective order until higher accuracy is achieved or the limit of the base learning algorithm is reached.
As you can see, boosting combines mainly the outputs from weak learners to create a strong learner that eventually improves the accuracy of the prediction model.
The method achieves this by putting weights on the samples of data. What this means is that boosting is used to track which data samples are successful and which are not in order to give heavier weights to datasets with the maximum misclassified outputs. These datasets are considered to be more complex and need more iterations to train the model correctly.
Here’s an example of face detection using AdaBoost, a boosting algorithm, for face detection in a scenario of binary categorization, where there are two categories, that is, faces versus background.
The general algorithm, shared on Wikipedia, is as follows:
Form a large set of simple features
Initialize weights for training images
For T rounds
Normalize the weights
For available features from the set, train a classifier using a single feature and evaluate the training error
Choose the classifier with the lowest error
Update the weights of the training images: increase if classified wrongly by this classifier, decrease if correctly
Form the final strong classifier as the linear combination of the T classifiers (coefficient larger if training error is small)
After boosting, a classifier constructed from 200 features could yield a 95% detection rate under a 10-5 false-positive rate.
You can see this YouTube video to learn more about Adaboost – short for Adaptive Boosting, a conventional Boosting algorithm in Python.
The Difference Between Bagging and Boosting in Machine Learning
Bagging and boosting are two popular ensemble methods in machine learning, where a set of weak learners combine together to create a strong learner to improve the accuracy of the model.
So, while bagging and boosting are both used in data mining to achieve similar results, the difference lies in how the ensemble is created. Bagging draws random subsets from the data at each iteration to fit new models. Boosting, however, samples the datasets that don’t fit the model well, or show a higher degree of error in the last iteration and creates a new model based on them which are averaged into the existing model.
In the table below, you can take a look at the difference between bagging and boosting:
Bagging
Boosting
Training data subsets are drawn randomly with replacement from the training dataset.
Each new subset contains the components misclassified in the previous models.
Bagging is used to tackle the over-fitting issue and reduce variance.
Boosting is used to reduce bias.
If the classifier is unstable or shows high variance, we need bagging.
If the classifier is steady and straightforward, with high bias, we need boosting.
In bagging, every model receives equal weight.
In boosting, models are weighted according to their performance.
It is used for connecting predictions of the same type.
It is used for connecting predictions that are of different types.
Each model is independently constructed.
Each model aims to solve the problems of the previous model and is, therefore, affected by the performance of the previously developed model.
Bagging and Boosting – Which Is the Better Alternative?
When we discuss bagging, the indication is usually toward random forest – which yields some decent results after having trained only one model. With bagging, you can also quickly find out the predictors that aren’t working and drop them out. On the contrary, boosting algorithms require meticulous tuning, which may be easy to set up and run but also time-intensive.
Thus, even though the results from boosting may be more precise, which is great for winning competitions, in real-life, the increase in performance versus the time and effort invested may not always make boosting the most practical ensemble learning method to use.
Conclusion
The world of machine learning holds endless possibilities in every domain, be it e-commerce, retail, finance, or medicine. With so many real-world applications, pursuing a course in machine learning with a focus on basic techniques is a great way to start a rewarding career in the field.
At Digital Vidya, you can learn more about ensemble methods like bagging and boosting in Python, which combine machine learning models to improve predictions. Apply these models to solve classification and regression problems, and brush up your theoretical as well as practical knowledge with a thoughtfully curated syllabus and hands-on assignments that will help to make you industry-ready.
Excited? Get in touch to know more or enrol in Digital Vidya’s Machine Learning Course here!







