
Introduction to Natural Language Processing:
Natural Language Processing (NLP) is a branch of computer science and artificial intelligence which is concerned with the interaction between computers and human languages. Natural Language Processing is the study of mathematical and computational modeling of various aspects of language and the development of a wide range of systems. These include the spoken language systems that integrate speech and natural language. Natural Language Processing has a role in computer science because many aspects of the field deal with linguistic features of the computation. It is an area of research and application that explores how computers can be used to understand and manipulates natural language text or speech to do useful things. NLP is a large and multidisciplinary field, so this blog can only provide a very general introduction.
- The three primary goals of this field are The investigation of human language understanding and generation – using the computer to express, test, and further develop theories of human cognition. This approach is part of the “cognitive modeling” aspect of artificial intelligence.
- The refinement and development of linguistic theories stressing generality, coverage and “linguistic soundness” of syntactic analyzers. This approach includes mathematically oriented analysis of formal languages.
- The construction of practical, using natural language interfaces and processing systems – often with concrete applications in mind. This approach includes the less-than-successful early machine translation efforts as well as the much more promising, and recently proven, natural language database query systems.
The three perspectives on Natural Language Processing are by no means independent, as illustrated by the lively discussions in the literature and in conferences where researchers representing each approach meet to compare notes, share results and criticize each other’s ideas and systems.
The first perspective, a scientific goal, is pursued to help us understand our language and ourselves. The second goal, also a scientific endeavor, focuses on studying language as a formal, mathematical object. The third goal, an engineering one, is pursued the very practical purpose of enabling virtually everyone to make direct, personal use of powerful computational systems without learning special computer languages.
The creation of machines that can interact in a facile manner with human remains far off, awaiting both improved information- processing algorithms and alternative computing architectures. However, progress in the last decade had demonstrated convincingly the feasibility of dealing with natural-language input in highly restricted contexts, employing today’s computers.
Basic concepts:
The research work in the Natural Language Processing with Python applications has been increasingly addressed in the recent years. The Natural Language Processing is the computerized approach to analyzing text and being a very active area of research and development. The literature distinguishes the main application of Natural Language Processing and the methods to describe it.
-
Natural Language Processing for Speech Synthesis:
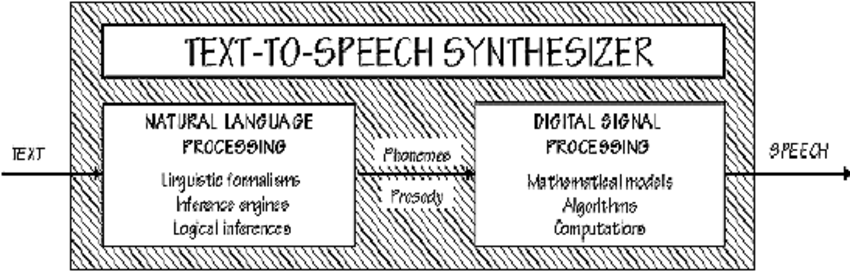
- This is based on the text to speech conversion i.e (TTS) in which the text data is the first input into the system. It uses high-level modules for speech synthesis. It uses the sentence segmentation which deals with punctuation marks with a simple decision tree.
-
Natural Language Processing for Speech Recognition:
- Automatic speech recognition system makes use of Natural Language Processing techniques based on grammar. It uses the context-free grammars for representing the syntax of that language presents a means of dealing with spontaneous through the spotlighting addition of automatic summarization including indexing, which extracts the gist of the speech transcriptions in order to deal with Information retrieval and dialogue system issues.
Working of NLP:
The most explanatory method for presenting what actually happens within a Natural Language Processing system is by means of the ‘levels of language’ approach. This is also referred to as the synchronic model of language and is distinguished from the earlier sequential model, which hypothesizes that the levels of human language processing follow one another in a strictly sequential manner.
Psycholinguistic research suggests that language processing is much more dynamic, as the levels can interact in a variety of orders. Introspection reveals that we frequently use the information we gain from what is typically thought of as a higher level of processing to assist in a lower level of analysis.
For example, the pragmatic knowledge that the document you are reading is about biology will be used when a particular word that has several possible senses is encountered, and the word will be interpreted as having the biology sense. Of necessity, the following description of levels will be presented sequentially.
The key point here is that meaning is conveyed by each and every level of language and that since humans have been shown to use all levels of language to gain understanding, the more capable a Natural language processing algorithms are, the more levels of language it will utilize.
-
Phonology:
- This level deals with the interpretation of speech sounds within and across words. There are, in fact, three types of rules used in the phonological analysis :
- Phonetic rules: It is used for sound within words.
- Phonemic rules: It is used for variations of pronunciation when words are spoken together.
- Prosodic rules: It is used to check for fluctuation in stress and intonation across a sentence.
- This level deals with the interpretation of speech sounds within and across words. There are, in fact, three types of rules used in the phonological analysis :
-
Morphology:
- Morphology is the first stage of analysis once input has been received. It looks at the ways in which words break down into their components and how that affects their grammatical status. Morphology is mainly used for identifying the parts of speech in a sentence and words that interact together. The following quote from Forsberg gives a little background on the field of morphology. The information gathered at the morphological stage prepares the data for the syntactical stage which looks more directly at the target language’s grammatical structure.
-
Syntax: Syntax involves applying the rules of the target language’s grammar, its task is to determine the role of each word in a sentence and organize this data into a structure that is more easily manipulated for further analysis. Semantics is the examination of the meaning of words and sentences.
-
Grammar: In English, a statement consists of a noun phrase, a verb phrase, and in some cases, a prepositional phrase. A noun phrase represents a subject that can be summarized or identified by a noun. This phrase may have articles and adjectives and/or an embedded verb phrase as well as the noun itself. The majority of natural languages are made up of a number of parts of speech mainly: verbs, nouns, adjectives, adverbs, conjunctions, pronouns and articles.
- Parsing: Parsing is the process of converting a sentence into a tree that represents the sentence’s syntactic structure. The statement: “The green book is sitting on the desk” consists of the noun phrase: “The green book” and the verb phrase: “is sitting on the desk.” The sentence tree would start at the sentence level and break it down into the noun and verb phrase. It would then label the articles, the adjectives, and the nouns. Parsing determines whether a sentence is valid in relation to the language’s grammar rules.
-
- Morphology is the first stage of analysis once input has been received. It looks at the ways in which words break down into their components and how that affects their grammatical status. Morphology is mainly used for identifying the parts of speech in a sentence and words that interact together. The following quote from Forsberg gives a little background on the field of morphology. The information gathered at the morphological stage prepares the data for the syntactical stage which looks more directly at the target language’s grammatical structure.
-
Semantics:
- It builds up a representation of the objects and actions that a sentence is describing and includes the details provided by adjectives, adverbs, and propositions. This process gathers information vital to the pragmatic analysis in order to determine which meaning was intended by the user.
-
Pragmatics:
- Pragmatics is “the analysis of the real meaning of an utterance in a human language, by disambiguating and contextualizing the utterance”. This is accomplished by identifying ambiguities encountered by the system and resolving them using one or more types of disambiguation techniques.
Introduction of NLTK Library:
NLTK is a popular library which is used for NLP. It provides a plethora of processing algorithms to choose from for a particular problem which is a boon for a researcher but a bane for a developer. It is a string processing library. It takes strings as input and returns strings or lists of strings as output. It was written in Python and has a big community behind it.
Examples of Natural Language Processing:
NLP is a way for computers to analyze, understand, and derive meaning from human language in a smart and useful way.
- Spell check functionality in Microsoft Word is the most basic and well-known application.
- Text analysis, also known as sentiment analytics, is a key use of NLP. Businesses can use it to learn how their customers feel emotionally and use that data to improve their service.
- Google Translate applies machine translation technologies in not only translating words but also in understanding the meaning of sentences to improve translations etc.
Summary:
Despite the challenges against them, Natural Language systems hold great promise in areas involving human-computer interaction. Great progress has been made towards developing practical applications with NLP systems in certain areas, other areas are still in need of work like Natural Language Processing in Artificial Intelligence and provide an open area for research for developing theories. There are also future implementations of the research, which assists in identifying the complex pattern in language. Further research can be conducted to identify its impact on individual learning, understanding of context, and effectiveness of NLP in writing and assessment procedure. Hope this Natural Language Processing tutorial is useful for the kickstart. To know more, read on the introduction to Text Analysis in Python.







