
Text Mining is used to help answer specific research questions. So the question is “What is Text Mining?” Say you want to answer “why cats sit on mats?” it would be impossible for you to read all the millions of research articles on the topic yourself. Here is where Text Mining can help. It filters large amounts of research and extracts the relevant information you need.
Let me explain the topic by giving some text mining examples, in the sentence – “Why cats sit on mats” the program would identify the ‘cat’ is the noun, ‘sit’ is the verb and ‘on’ is the proposition. But it is not just a search tool, it can also understand that the ‘cat’ is an animal, ‘sit’ is an action, and a ‘mat’ is an object.
It then identifies and maps patterns and trends across the millions of articles. For example, it can even tell us if most of the cats who sit on mats come from cold climates. This detailed relevant information helps us determine what additional research is needed in order to answer our question.
Download Detailed Brochure and Get Complimentary access to Live Online Demo Class with Industry Expert.
So now we can go back into the lab with a head start in order to do further research to find out the exact reasons. Although it might seem easy, text mining requires a lot of different tools and resources to make this work. Read on to find out more.

What is Text Mining and How does it work?
Researchers can solve specific research questions by using text-mining. you can text mine by first collecting the content you want to mine. For example, within academic articles, then you can apply a text-mining tool which helps extract the information you need from large amounts of contents.
The tool extracts by learning how to find information from each article. It examines complex research content containing unique language, abbreviations, codes, and symbols. Researchers then end up with a long list of extracted words and sentences.
The text-mining
Column 1
Column 2
Column 3
tool also understands how the words relate to one another and can analyze the results. It enables researchers to see emerging trends and patterns, impossible to do if you had to read all the content yourself. This results in new insights which help answer their research questions.
Researchers can share their results with the research community as a news article or as a resource like a searchable database.

The Concept of Text Mining
Text Mining is a tool which helps in getting the data cleaned up. Text mining techniques are basically cleaning up unstructured data to be available for text analytics
If we talk about the framework, text mining is similar to ETL (i. e. Extract, Transform, Load) which means to be able to insert data into a database, these steps are to be followed. For example, text categorization, text clustering, concept/entity extraction, sentiment analysis, document summarization, production of granular taxonomies, entity relation modelling.
Areas of Text Mining
Information Extraction -> Data Mining -> Natural Language Processing -> Information Retrieval
Information Extraction (IE) – IE is the process of automatically obtaining structured data from unstructured data. This action includes Natural Langauge Processing
Data Mining (DM) – Data Mining looks for patterns in data. It can be more described as the retrieval of hidden information from data. Text-Mining in Data-Mining tools can predict responses and trends of the future. It enables businesses to make positive decisions based on knowledge and answer business questions.
Natural Language Processing (NLP) – The purpose of NLP in text mining is to deliver the system in the knowledge retrieval phase as an input.
Information Retrieval (IR) – IR is considered as an extension to document extraction. IR systems help in to narrow down the set of records that are associated with a specific problem. Text mining involves applying complicated mining algorithms to large-scale documents. By reducing the number of documents, IR can increase the speed of the analysis significantly.
How to perform Text Mining?
Python and R are the most famous text mining tools out there for text mining.
The following steps are to be followed for Text-Mining Python and Text mining in R,
Information Retrieval | Data Preparation and Cleaning | Segmentation | Tokenization | Stop-word numbers and punctuation removal | Stemming | Convert to lowercase | POS tagging | Create text corpus | Term-Document matrix
Tokenization
The process of splitting the whole data (corpus) into smaller chunks or smaller words usually single words is known as tokenization (N-Gram model or Bag of words Model)
Stemming and Lemmatization
We do lemmatization in order to prevent data duplication by linking words with the root word. For instance, the words – [big, bigger and biggest] all mean the same and it will cause data redundancy.
Stop-word numbers and punctuation removal
To go from raw text to fitting a deep learning model. We have to clean the text first, which means – splitting it into words and checking punctuation and case (by converting to lower case).
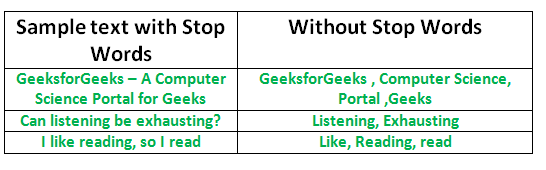
Stop Words: The search engine has been programmed to ignore these stop words during indexing entries and retrieving them as the result. Stop words are no use in analytics which will include words like “the”, “a”, “an”, “in”, “is”, “and” etc.
POS-tagging
POS-tagging stands for Part of Speech tagging which is part of NLP. It is one of the main components of almost any NLP analysis. The process of POS-tagging simply means labelling words with their relevant Part-Of-Speech (Noun, Adjective, Verb, Pronoun, Adverb, …).


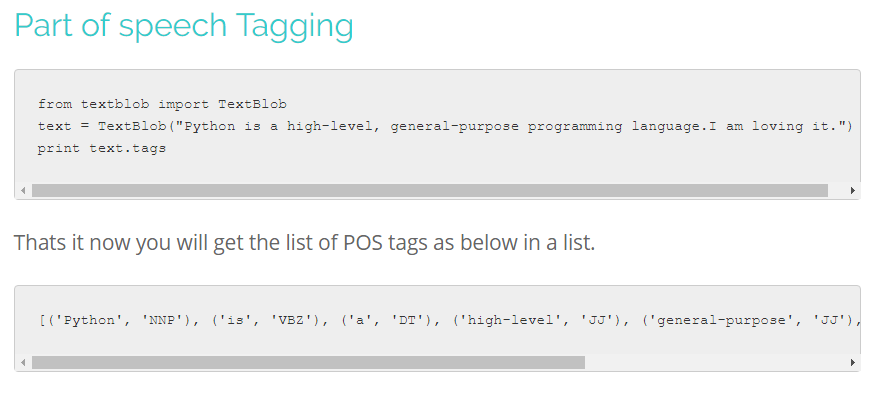
POS-tagging – python code snippet
Create Text Corpus

Term-Document matrix
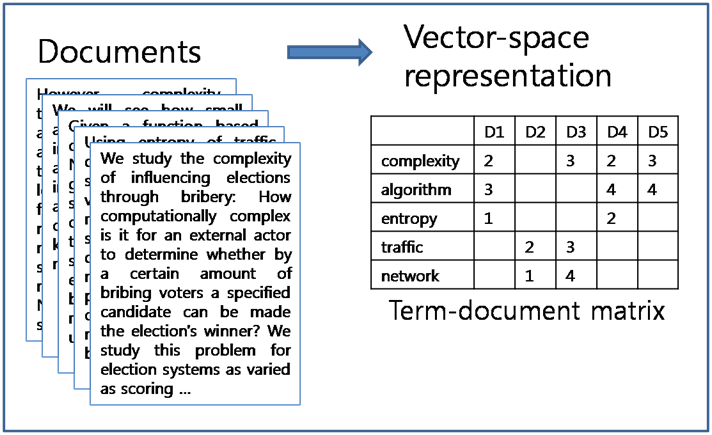
Association Mining Analysis – Real-world text mining applications of text mining
An application on which some guys were working called “Adverse Drug Event Probabilistic model”. In this model, we can check the following, on taking a particular medicine what adverse events are caused by which adverse event.
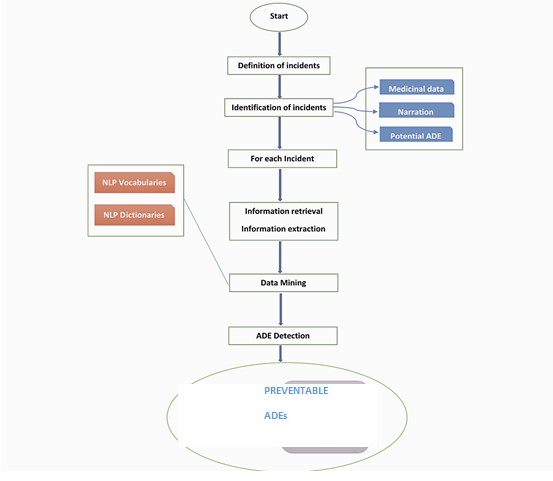
—
Inputs, Excerpts and Image Credits:
Why cats sit on mats? – an original concept by Elsevier.


YouTube videos on text mining published by the official Elsevier
www.geeksforgeeks.org/removing-stop-words-nltk-python/
machinelearningmastery.com/clean-text-machine-learning-python/
www.learnsteps.com/part-of-speech-tagging-noun-phrases-sentences-and-tokenization-for-natural-language-processing/
www.speedlab.io/en/2017/03/08/creation-semantic-variables-based-document-term-matrix-dtm/








A well explained article on text mining with good examples.
Hi Suhaib, Nice blog about text mining.