
Before we get into core concepts like collaborative filtering recommender systems and collaborative filtering algorithms, let’s understand recommender systems.
A recommender system aims to predict a user’s preference, in order to ‘recommend’ an item, that could be a product like clothes, or could be movies, services, etc., recommender systems have become very important today because of the surplus of options in every domain, and they help companies better place their products or services for increased movement.
There are two ways of building a recommender system; one is Content-based, and the other is Collaborative Filtering. We’ll be looking at Collaborative Filtering in-depth in this article, along with Collaborative Filtering examples.
35% of Amazon.com’s revenue is generated by its recommendation engine.
There are two ways, or senses, in which collaborative filtering runs recommender systems, and that is a narrow one and a more general one.
In the narrower sense, collaborative filtering works by predicting one user’s preference, by collecting and studying the preferences of many other similar users.
Download Detailed Brochure and Get Complimentary access to Live Online Demo Class with Industry Expert.
For example, if user A and user B both prefer the same washing machine, the other preferences of user B might be something user A will be interested in since their tastes and needs are similar. This is, of course done by taking into consideration many different users and numerous preferences and reactions, hence the term, collaborative filtering.
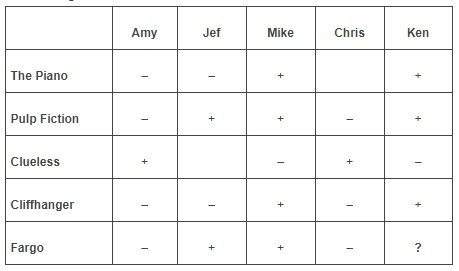
In a more general sense, collaborative filtering is the process of predicting a user’s preference by studying their activity to derive patterns.
For example, by studying the likes, dislikes, skips and views, a recommender system can predict what a user likes and what they dislike.
The difference between collaborative filtering and content-based filtering is that the former does not need item information, but instead works on user preferences.
Types of Collaborative Filtering
1. Memory-Based or Nearest Neighborhood Algorithm
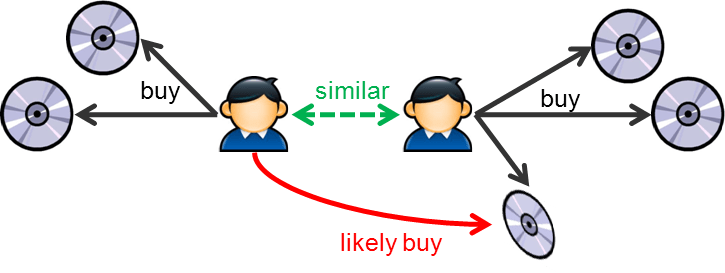
This method uses a rating system to predict the preferences of one user by taking into consideration the preferences of a similar user, or the ‘neighbor’. There are two ways to calculate preferences here, user-based Collaborative Filtering and item-based Collaborative Filtering.
Let us first consider user-based Collaborative Filtering. Let’s say we have a matrix of ratings n x m, for user uᵢ, i = 1,…n and item pⱼ, j=1,…m. Let’s say we need to predict the rating of item rᵢⱼ, an item j that user i has not watched/rated. How this method works, is to calculate user i’s preferences and match them with other users, select the top X similar users, take their ratings for the item rᵢⱼ, and find the weighted average to predict user i’s possible rating/preference of the item.

Taking into consideration the fact that some users tend to be too lenient, giving high ratings for items they don’t really enjoy, while some users tend to be too strict, giving low ratings even for items they like, this method of Collaborative Filtering corrects the formula to get rid of the bias. To correct this, we subtract each user’s average rating of all items when computing the weighted average and then add it back for the target user:

Similarity can be calculated in 2 ways: Pearson Correlation and Cosine Similarity.

Summing up this method, the idea is to find users most similar to our target user in terms of preference, weigh their ratings for an item, and predict that as the potential rating for our target user, for the selected item.
In Item-Based Collaborative Filtering, we compare two items and assume them to be similar when one user gives the two items similar ratings. We then predict that user’s rating for an item by calculating the weighted average of ratings on most X similar items from this user. See the image below as an example.
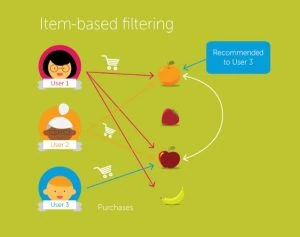
2. Model-Based Collaborative Filtering
In this method of collaborative filtering recommender systems, different data mining and machine learning algorithms are used to develop a model to predict a user’s rating of an unrated item. Some examples of these models are Bayesian networks, clustering models, singular value decomposition, probabilistic latent semantic analysis, multiple multiplicative factor, latent Dirichlet allocation and Markov decision process-based models.
3. Hybrid Collaborative Filtering
This method combines the memory-based and model-based Collaborative Filtering systems to eliminate limitations like sparsity and loss of information. This method, however, is more complex to build.
Collaborative Filtering Example
To get a good understanding of collaborative filtering recommender systems, let us take a real-time collaborative filtering example and build a collaborative filtering algorithm in Python. The first step is to define the dataset. If you’re a beginner in Python, check out this knowledge article:
1. Dataset
For this collaborative filtering example, we need to first accumulate data that contains a set of items and users who have reacted to these items. This reaction can be explicit, like a rating or a like or dislike, or it can be implicit, like viewing an item, adding it to a wish list, or reading an article.
These data sets are usually represented as a matrix that consists of a set of users, items, and the reactions given by these users to these items. Here’s an example:
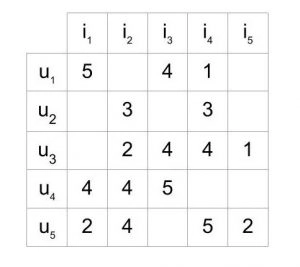
This matrix represents five users u1-u5, who have rated five items i1-i5, between ratings 1-5 (also no ratings). In most cases, these matrices have more empty cells than full ones, because it is very unlikely for many users to rate many of the items in the list. This is known as a sparse matrix.
You can use this a list of high-quality data sources for your collaborative filtering algorithm projects. A good place to start is MovieLens 100k dataset which contains 100,000 ratings for 1682 movies given by 943 users, with each user having rated at least 20 movies.
While the dataset has many useful fields, the ones we are focusing one in particular are:
u.item: the list of movies u.data: the list of ratings given by users
The u.data file contains a separate list of ratings and user ID, item ID, rating, and timestamp. Here’s an example:
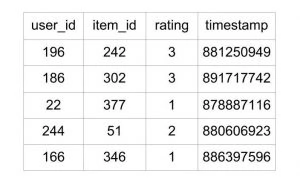
The entire file contains data for 100,000 such ratings.
2. Creating the Collaborative Filtering Algorithm
The idea behind executing this project is to 1. Identify users with similar preferences and then 2. Predict a rating for a movie by a user, who has not yet rated it. We will also have to take into consideration the accuracy of our results.
1 and 2 are achieved using different sets of algorithms. An important point to remember is that we are not concerned about the sample users’ age, demography, etc. or the movies’ genre, etc. All we are concerned with is implicit and/or explicit ratings for these movies by these users.
In order to measure the accuracy of our result, we can use options like Root Mean Square Error, or Mean Absolute Error.
Memory-based Collaborative Filtering Algorithm
In this method, we are trying to predict the rating R that a user U would possibly give an item (the movie) I.
The first step is finding users who have similar preferences to user U, then calculate the rating R.
Here’s an example of how we find users with similar preferences. Consider the small dataset:

These are ratings for 2 movies, given by 4 users A, B, C and D. Plotting the ratings, the graph looks like this:
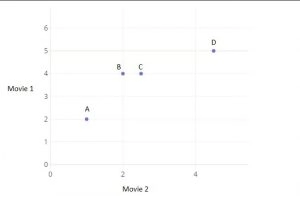
The distance between plot points is one way to get an idea about similarities in interest. We can use the following program to calculate the distance:
from scipy import spatial
a = [1, 2] b = [2, 4] c = [2.5, 4] d = [4.5, 5] spatial.distance.euclidean(c, a) >2.5 spatial.distance.euclidean(c, b) >0.5 spatial.distance.euclidean(c, d) >2.23606797749979
We’re using the scipy.spatial.distance.euclidean function to calculate the distance. We are calculating the distance of C from A, B, and D. We can see, from the result and also from the table itself, that C is closest to B. But also, we’d like to know out of A and D who is closest to C. in terms of distance, we might say D, but looking at the table we might say that A and C are more aligned because they both like movie 2 twice as much as movie 1 (considering ratios and not the actual rating) while user D likes both movies almost equally, indicating their preference may be different. What the Euclidean distance cannot predict, we can possibly derive from the angle of the line connecting the users. Joining the users, the graph would look like:
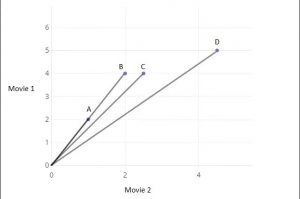
We can see that the lesser the angle between two lines, the more similar their references. To find this in the program, we can run the following:
from scipy import spatial a = [1, 2] b = [2, 4] c = [2.5, 4] d = [4.5, 5] spatial.distance.cosine(c,a) >>0.004504527406047898 spatial.distance.cosine(c,b) >>0.004504527406047898 spatial.distance.cosine(c,d) >>0.015137225946083022 spatial.distance.cosine(a,b) >>0.0
You can see that the cosine similarity between a and b is 0, indicating close similarity. Using Euclidean distance and cosine similarity is 2 of the different methods you can use to calculate similarity in preference.
3. Calculating The Rating
Once we have identified users with similar preferences to our user U, we go about predicting the rating R U would give for a movie if they have not yet rated. Again, there are many ways to go about this.
One straightforward way is to find the average of the ratings given for that movie by the similar top users. The mathematical expression would be:
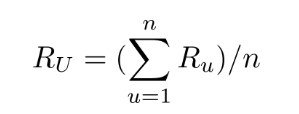
You can also go for a weighted approach if the in the top similar users there is a lot of difference in opinion. That would mean giving the closest similar user more weight and then descending weights. The expression would be:
 Limitations of Collaborative Filtering
Limitations of Collaborative Filtering
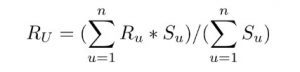 Limitations of Collaborative Filtering
Limitations of Collaborative FilteringOne being, it does not take into consideration metadata. Users might rate a movie based on their preference for the actor in it, for example, but collaborative filtering will not take this into account.
Another drawback is that collaborative filtering is not very effective unless a lot of users have rated a lot of items. Only then can it make the best match for a similar audience and then predict the rating.
Since Collaborative Filtering needs huge data sets, to be able to get users with close similarities, there is often the problem of data sparsity. As we saw earlier, a sparse matrix is one with more empty cells than full ones, which is almost always the case.
Scalability is another issue, as the Collaborative Filtering algorithm is usually written considering n users. As the data set grows, the overall program can become massive.
Applications of Collaborative Filtering Recommender Systems

Collaborative Filtering finds the highest use in the social web. You will see collaborative filtering in action on applications like YouTube, Netflix, and Reddit, among many others. These applications use Collaborative Filtering to recommend videos/posts that the user is most likely to like based on their predictive algorithm.
Collaborative Filtering is a popular method for recommender programs, despite the limitations. It is also used in e-commerce platforms to recommend products, based on purchases by users of similar preferences or tastes.
As a programmer, you will need to mix algorithms to make Collaborative Filtering more precise, and also mix methods or prediction to get the most accurate results. The Recommender Systems chapter in the Mining Massive Dataset book is also a great source of information on Collaborative Filtering.
We also have a Complete Guide on How to Become a Data Scientist, which is something most machine learning enthusiasts aspire to become.
To get the right data science skillset, you should enroll yourself in a Data Science Course. This will help you to elevate your career as a Data Scientist.







