
Introduction to Data Science
Data Science (also known as data-driven science) is a discipline that covers scientific methods, processes and systems to pull out insights or knowledge from various forms of data, structured or unstructured, not different from KDD (Knowledge Discovery in Databases).
We can say that it is a concept for unifying data analysis, statistics and methods related to them for understanding and analyzing actual phenomena using data. Data science uses theories and techniques adopted from many other fields in areas such as statistics, mathematics, computer science, and information science, particularly from subdomains in data mining, machine learning, cluster analysis, classification, visualization, and databases.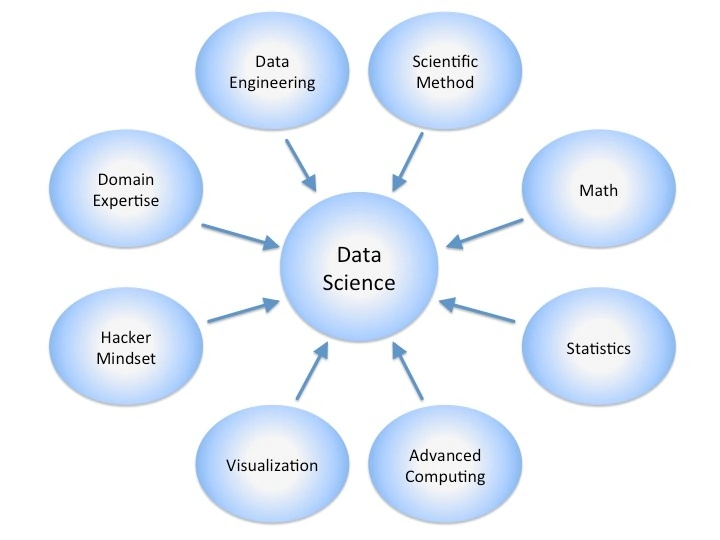
Data science itself as an academic discipline and a profession is new being conceived within the first 10 years in the 21st century with a background in the fields mentioned earlier. Students learning data science introduction are introduced to those fields as various courses and then given exercises that combine them into data science. Also, hacking is not left out, although in a positive manner, because it is a contributing discipline to data science, however, it is not taught as a course. A well-groomed data scientist will be very proficient in all the parent disciplines, studying each of them and using their combination for problem-solving.
Data science as at today is known to rise from the cloud computing/big data world and complexity science which implies that it is an advanced discipline, which requires sound knowledge in parallel processing, petabyte-sized NoSQL database, map-reduce computing, advanced statistics, complexity science and machine learning. This, therefore, means that data science can be properly learned at the Masters and Doctorate level. However, it is believed that data science is more of the mindset just as it covers the skillful use of tools. Students are therefore engaged in the early stages of their careers so as to make them think holistically on data science.
Combination of various disciplines
The introduction to data science combines eight parent disciplines which contribute to data science and they generate questions a data scientist needs to ask when solving problems. It is expected that the data scientist would likely be an expert in one or two of those disciplines and proficient in five or six of the others. This requires data science to be practiced as a team with various members having individual expertise across the various disciplines.
The various disciplines when taking an introduction to data science are discussed below:
1.) Data Engineering
Data Engineering covers the acquiring, ingestion, transformation, storage and retrieval of data. It also includes the addition of metadata to data and since all these activities inter-relate to each other, the data engineer should solve these problems as a single entity. For instance, we need to know how we will plan to store and retrieve data so to make a good atmosphere for ingestion. A good understanding of the nature of data science problems that are meant to be solved is required so as to formulate a proper data acquisition and management plan. Once this is developed, the data engineer can go ahead to implement it for data management systems.
- Acquiring: Is the act of laying hands on the data. Various questions are asked by the data engineer in the data scientist pertaining to where the data comes from, what it looks like and how the team can get access to the data.
- Ingestion: Ingesting involves getting data from its source into the computer used for analysis. Questions asked by the data engineer part of the data scientist are based on how much data is coming, how fast it comes and where the data needs to be put and if there is enough disk space for the data as well as if any incoming data needs to be filtered.
- Transformation: This involves the conversion of data from its initial form to the form required for analysis. Questions are asked on what form the raw data is and what form the processed data needs to be.
- Metadata: This is known as data about data. What we want to know about this is where the data collected from and when it was collected. Metadata can be added or derived both at ingestion and transformation time.
- Storage: This process involves saving the data into a management system. Things to be known are what kind of system would be the best for saving data, how fast the system would be and how much extra space would be needed. Of course, file systems can be used for storing data in files; they are very fast but have little functionality. Data can also be stored in a database which is relatively slow compared to the file system.
- Retrieval: This process comprises of how to get the data back out of the system. Questions to be asked are how questions about the data will be asked and how data would be displayed. We can go through the data via a query system and display the various subsets of the data in the table.
2.) Scientific method
Scientific Method is another area in data science introduction which is a process for acquiring new knowledge and this is done by applying reasoning principles on empirical evidence extracted from hypothesis testing through experiments that are repeated. A scientist would naturally want to know the evidence and standard of acceptance for the evidence when someone makes an assertion pertaining to a fact.
- Reasoning principles: Logical reasoning is in two forms – deductive and inductive. Deductive reasoning is derived from specific conclusions depending on general principles while inductive reasoning leads to general principles from specific observations.
- Empirical Evidence: This is data produced by an experiment or experiment. Empirical evidence is in contrast to data gotten from arguments of logic or conclusions that are made from myths and legends.
- Hypothesis Testing: This form of testing asserts 2 propositions of which just one is true. Empirical evidence is gathered by the scientist for and against each proposition but then one is accepted while the other is rejected. Actually, one of these hypotheses would be the null hypothesis which is a proposition which pertains to the way the universe works according to our understanding, while the other is the alternative hypothesis which is a proposition about how we assume the universe works.
- Repeatable Experiments: An experiment is known to be a methodical trial and error procedure which scientists carry out with the aim of proving, disproving or establishing a form of a validity of a hypothesis. These experiments vary on various factors but depend on repeatable procedure always.
3.) Mathematics
The introduction to data science has a very important part which is Math, one of the foundation disciplines. Math is the study of structure, quantity, change and space and when these concepts are used in practical problem solving, it becomes applied mathematics.
- Quantity: Quantity simply means numbers. Questions asked by the mathematician in a data scientist pertain to how can the thing in question be represented in numbers and what kind of numbers would represent it. Such numbers can be real numbers, complex numbers, integers, and fractions.
- Structure: Majority of the sets of mathematical objects show internal structure. What kind of internal structure does the thing in question have and what set of equations would expose the structure are questions asked. Algebra is used in operating and representing our data structure.

- Space: Things investigated on normally have a relationship with two-dimensional or three-dimensional space. The data scientist asks “does the thing in question have a spatial component, either theoretical or real?” and “how can I capture and represent the spatial component?” Such component could either be latitudinal or longitudinal. Also, trigonometry and geometry are used for operating and representing spatial components.
- Change: There are always changes in the things we investigate over distance or time and the data scientist would ask himself if the relationship between the things investigated change and how can the changing relationship be described. Calculus is what is used to operate and represent changing relationships within the data.
- Applied Math: Applied Mathematics is math using specialized knowledge; this is actually the mathematics practiced by Data scientists.


4.) Statistics
Statistics is also another core area in data science introduction and it is defined as the study of collecting, organizing, analyzing and interpreting data. Statistics involve various methods used to explore data, creating models, discovering patterns and relationships, and making forecasts for the future. It has the straightest line pedigree to data science.
- Collection: The statistician makes sure that generation and collection are observed to allow appropriate conclusions to be drawn. This is done by the creation of research design which includes experimental design governing data collection.
- Organization: The statistician also makes sure that collected data is coded and archived so that the information gotten is kept and utilized not just for project analysis but sharing with others. He creates a data dictionary which happens to be database neutral while a data engineer working with him creates a database specific.
- Analysis: When working with a mathematician, the statistician summarizes, aggregates, correlates and makes data models. The statistician has expertise in analyzing data by making use of inferential and descriptive statistics which includes making summaries of the data and testing for differences.
- Interpretation: The statistician reports results and summarized data in comprehensible ways for those who would make use of them when working with both a visual artist and subject matter.
5.) Advanced Computing
Advanced computing involves the heavy lifting of data science. Computer programming is the process of writing, designing, debugging, testing and maintaining the source code of computer programs. The source code in question is written in one or more programming languages and the essence of programming is creating a set of instructions used by computers for performing certain operations or exhibiting certain characters.
- Software design: Software design is the process of converting the purpose and specifications of a software into a specific plan which includes algorithm implementations and low-level components in an overall architectural view.
- Programming language: This is an artificial language designed for communicating instructions to a computer. These languages are used for creating programs that control the computer’s behavior other external devices like robots, printers and disk drives.
- Source code: This is a collection of computer instructions written by using some computer language which is humanly readable mainly as text. The source code, when executed is translated into a machine code which the computer is able to read and execute.


6.) Visualization
Visualization is known as the visual representation of abstract data for reinforcing human cognition. Such abstract data include both numerical and non-numerical data like geographic information and text. Graphic design is known to be a creative process undertaken so as to convey a particular message to an audience.
- Creative Process: This is the process of making something worthwhile and original. Such process includes conceptual blending and divergent thinking.
- Data Abstraction: This is the handling of data bits in purposeful ways. This means that we have to visualize data manipulations that are meaningful in relation to the problem we are trying to solve.
- Information Interesting: Naturally, humans give attention to interesting or attractive things because they are pleasing to the senses. The visual artist part of a data scientist should ask himself how he would be able to visualize the content of the data so it would be pleasing.
7.) Mindset of a Hacker
Hacking is very important for almost everyone taking data science introduction because it is the special sauce! Hacking is the process of one modifying his own computer system which includes building, rebuilding, creating hardware, software or peripherals so as to make it better, faster, make it have additional features and make it perform actions it wasn’t built for initially. For a data scientist, hacking goes beyond just the computer system to the whole system of solving data problems. Data science hacking comprises of creating new models, seeking new data structures and putting together all the parent disciplines in an unconventional manner.
8.) Domain Expertise
This is the gum holding data science together. The significance of domain expertise is for a data scientist to have proficiency, special skills or knowledge in a certain area. Any domain knowledge can be a subject in data science as a whole and can include areas like physical and biological sciences, medicine, politics demographics, marketing, literature and even information security. Every team of data scientists must have at least one individual who is an expert on the problem being solved depending on the subject matter.
Introduction to data science is wider than what we have discussed so far but for whatever reasons, the aforementioned disciplines cannot be overlooked because they lay the foundation of data science as a course and profession.







