
Named after co-creator Doug Cutting’s son’s toy elephant, Hadoop is an open-source software utility which enables the use of a network of multiple computers to solve problems involving huge amounts of data. Let’s start with In-depth Hadoop Tutorial.
How huge? Every day, humans generate over 2.5 billion gigabytes of data and it is rising sharply.
All of this data is useful in a myriad of applications (apparently including this big data Hadoop tutorial).
An article on the United Nations’ webpage quotes, “Data is the lifeblood of decision-making and the raw material for accountability.”
This Hadoop tutorial tries to compile all the important information you need to know. Let us go check.
What is Hadoop?
A 2016 paper by the founders of Hadoop sheds light on its birth.
In 2002-03, Google started work on its Google File System (GFS), a distributed file system and subsequently on MapReduce, another thing (which we will see soon) helpful in dividing work among a number of computers.
These were a part of the Nutch project, and later, the Hadoop subproject.
Hadoop 0.1.0 was released on April 2006 and has since seen a lot of contributions.
Its practical applications are extraordinary, such as the use in analyzing large amounts of patients’ data to predict which patients are suffering from life-threatening risks and which aren’t, more accurately than human doctors.
Although we won’t be immediately learning to diagnose serious diseases today, this Hadoop tutorial for beginners will certainly give you a basic idea of how it is done
Key Features of Hadoop
Developed by Apache Software Foundation, Hadoop runs on a cluster of multiple computers connected in a network and processes data in parallel.
It boasts of a number of great features. Let us see what makes Hadoop so awesome before we thoroughly understand ‘What is Hadoop?’:
1. Open Source
It is a framework that is free to use or even distribute, and its source code can be modified to achieve specific results.
2. Scalable
It can run on a single machine, and it can be scaled to run on hundreds of machines without any downtime, dynamically.
3. Fault-Tolerant
The framework creates replicas of data on different machines in the cluster (a group of machines), which means that even if one of the machines goes down (even if it burns down to ash and smoke), Hadoop will have not lost any data and will continue working.
4. Runs on Commodity Hardware
As if it wasn’t enough for Hadoop to impress by being open-source, it turns out, it can be run on inexpensive, everyday computer systems, i.e. commodity hardware, thus proving itself highly cost-effective.
Any big data Hadoop tutorial will tell you that cost-effective is a major feature of Hadoop, given two key features of being open source and commodity hardware compatibility.
Hadoop’s market is growing significantly, not simply because this Hadoop tutorial says so, but it is evident from statistics.
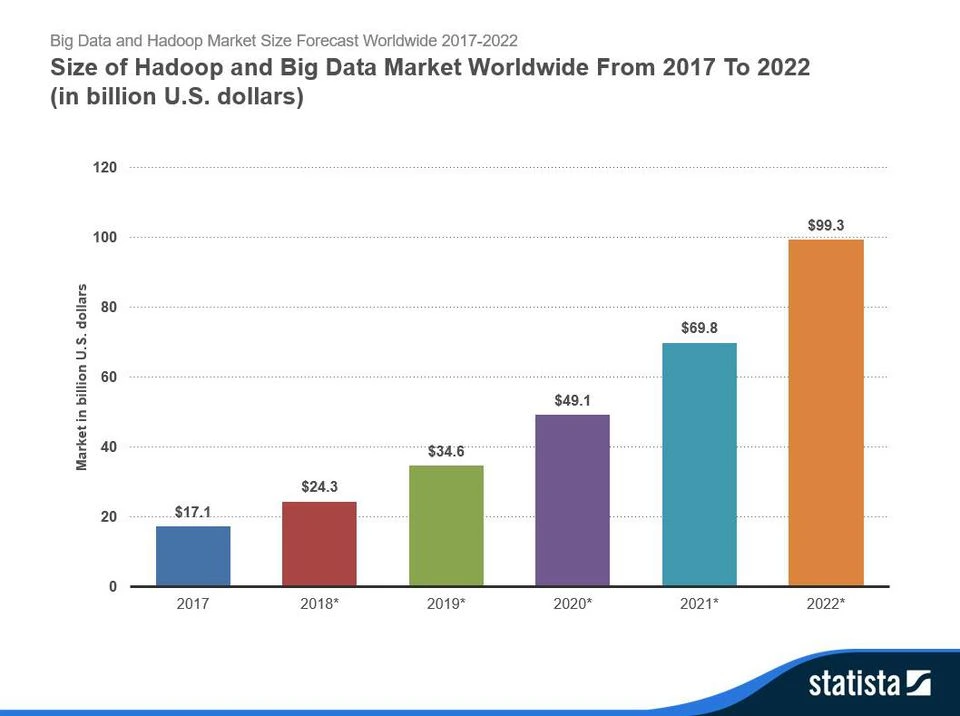
Architecture
Computer architecture is a term that specifies the various parts and their relations in a system.
A considerable amount of long and intricate description of Hadoop’s architecture can be given, and if you are interested, we suggest you explore some other Hadoop tutorial that does it.
As far as Hadoop is concerned, it consists of three major components that take care of the main functioning along with additional components built around the main ones to form an ecosystem together which perform the processing of massive amounts of data.
Hadoop Basic Components
Hadoop is built on three important core components, that take care of the data distribution in the network, resource allocation, and processing.
There can be a separate detailed Hadoop tutorial on them, but for beginners, let us outline all components in brief.
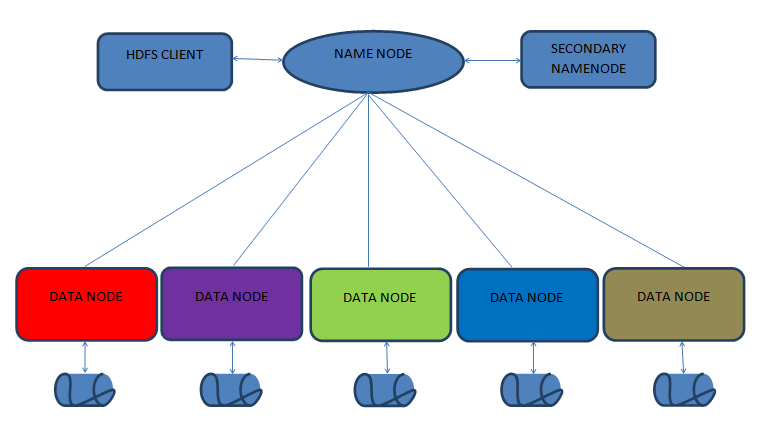
1. HDFS (Hadoop Distributed File System)
Like Google’s original GFS, the distributed file system is what allows huge volumes of data to be broken down and processed on various machines.
The data is split into blocks of default size 128MB each and stored distributedly across various computers.
There is also a replication of the blocks as per the replication factor that replicates the data blocks and stores on multiple machines thus making it fault-tolerant as discussed before.
The replication and storage of blocks in various machines (nodes) also increases availability by allowing a piece of data to be accessed from the nearest node.
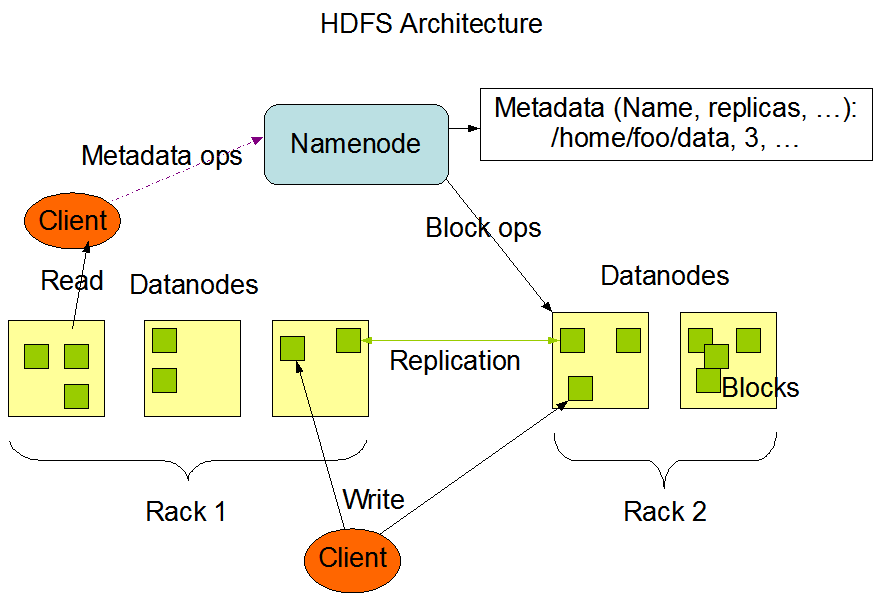
The HDFS runs in a master-slave fashion.
An HDFS cluster consists of a single master server called a NameNode and several slave nodes called DataNodes. We will discuss these in a later section of this Hadoop tutorial.
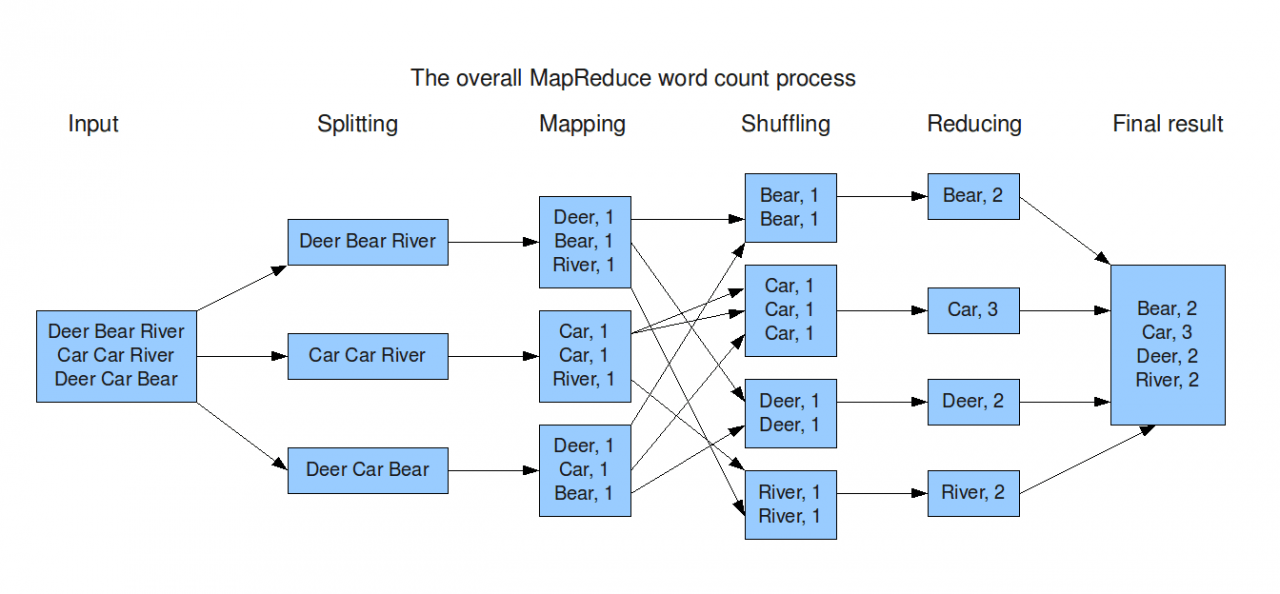
2. MapReduce
MapReduce is the programming model that makes the scalability of Hadoop possible by allowing it to run on a cluster of hundreds of computers.
Said to be the heart of Hadoop, it moves the computation closer to the data. Let us break it down into the two separate tasks that it does.
The first task is to ‘map’, which does the sorting of data into key/value pairs (for example CITY is a key and BANGALORE is a value, put together in a pair).
The reduce part takes this mapped data and further processes (reduces) it to give the final result in the form of sorted data that is even smaller than the mapped part.
3. YARN
With a funny name of ‘Yet Another Resource Negotiator’, it is the part of Hadoop that manages the resources, just as a manager may manage resources among many subordinate employees.
Resources such as CPU, memory, disk, and network are allotted optimally. YARN is also called a job scheduling/monitoring component.
See the image below for a simplified depiction of how YARN manages resources.
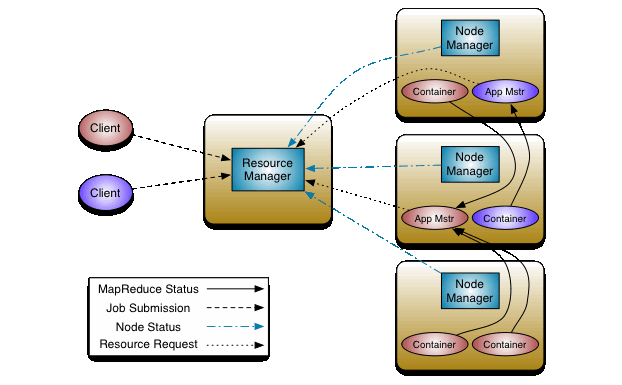
The node managers seen in the image are like area managers that manage resources in respective nodes and report to the main resource manager.
The ApplicationMaster is a per-application authority that negotiates resources with the node manager, where an application can be a single job or multiple in a DAG form. Containers are where the tasks finally run using the resources.
A lot can be said about the core components of Hadoop, but as this is a Hadoop tutorial for beginners, we have focused on the basics.
Hadoop Ecosystem
The core of Hadoop is built of the three components discussed above, but in totality, it contains some more components which together make what we call the Hadoop Ecosystem.
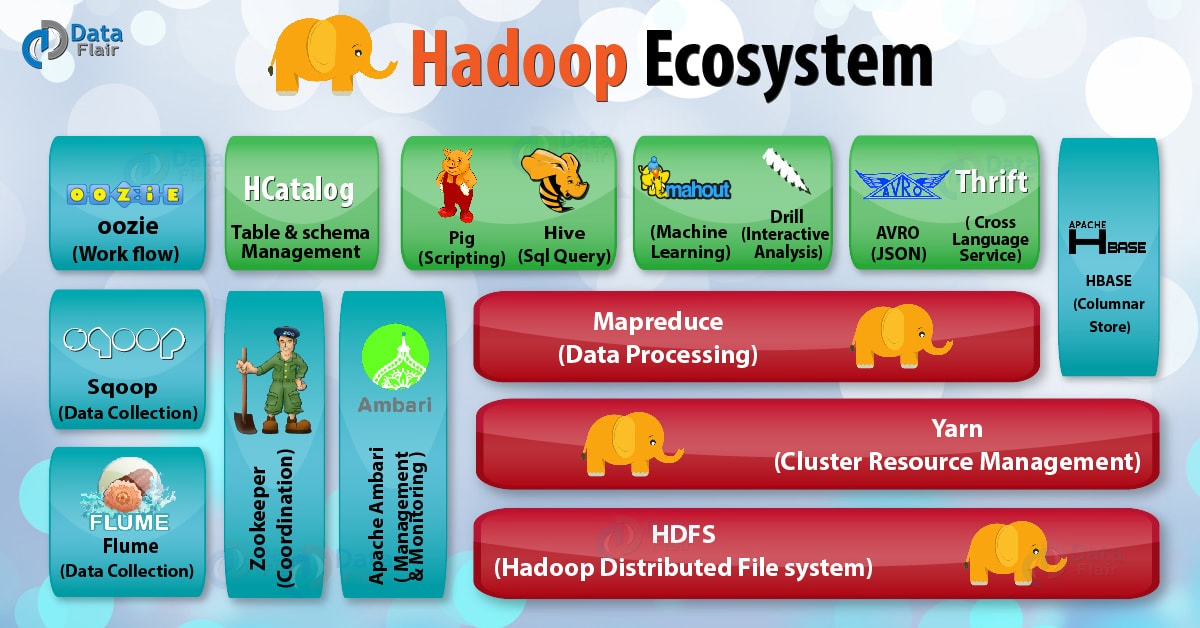
The three large red rectangles show our core components, which we have covered earlier in this Hadoop tutorial.
Besides those, the other squares and rectangles show additional components, some of which are discussed below:
1. Hive
For people conversant with SQL, Hive uses a much similar language to generate queries called HiveQL and translates these queries into MapReduce jobs to finally execute on Hadoop.
2. Pig
A high-level language platform that uses PigLatin, an SQL like language that requires much shorter codes.
The loading of data is done first, followed by functions such as sorting, grouping, joining, etc. and in the end, the result can be dumped on screen or stored in HDFS.
3. HBase
It is a distributed NoSQL database that supports all types of data.
HBase is written in Java and is capable of handling large sizes of databases. It provides real-time access to read or write data in HDFS.
4. Avro
It provides data serialization and data exchange services for Hadoop which can be used together or independently.
Big data is able to exchange programs written in different languages using Avro.
5. Mahout
The word Mahout in Hindi means the elephant rider or trainer. If Hadoop is an elephant, Mahout is a framework for creating machine learning algorithms.
6. Sqoop & Flume
Both of these are systems that help the ingesting of data in the Hadoop.
While Flume can ingest unstructured or semi-structured data, Sqoop can work with structured data as well. It imports or exports data between Hadoop and external sources.
7. Ambari
It can be viewed as a manager of the cluster. It includes software for the provisioning, monitoring, and management of the cluster.
8. Zookeeper
Mainly responsible for maintaining coordination between various services in Hadoop’s environment, it takes care of synchronization and configuration maintenance.
9. Oozie
Oozie streamlines the workflow by sequencing multiple jobs into a single logical unit while providing the flexibility of easy start, stop or rerun of jobs.
Once you have familiarized yourself adequately with the basics of Hadoop, you can try learning more about the Hadoop ecosystem in another Hadoop tutorial on the ecosystem.
Hadoop Daemons
Daemons are nothing but the processes that run in the background. They are classified as follows:
1. NameNode
It is also known as Master Node and it manages file system namespace and regulates access to files by clients.
In other words, it keeps a directory tree of all files in the system and tracks the data across the cluster, while not storing the actual files itself.
In simpler words, it stores only the metadata about the number of blocks, which data is stored in which DataNode, etc.
2. DataNodes
These are a number of slave nodes that contain the actual blocks of data to be processed.
They are in charge of replicating data blocks (which gives Hadoop its fault resistance), as well as erasing blocks.
3. Secondary NameNode
It works as a helper daemon by creating checkpoints of metadata that can be used to rebuild the filesystem metadata in the case of failure of the NameNode
4. NodeManager
As seen in YARN, it manages resources with the containers in a node while communicating with the main resource manager (YARN)
A fun way to learn more about HDFS and the daemons besides this Hadoop tutorial can be found here.
Hadoop Flavors
If you ask an expert “What is Hadoop?”, he will say it is one of the distribution software that is either free or not, general or customized.
The basic Hadoop framework is open-source and is distributed by the Apache Hadoop Foundation.
Although free of cost, this version is a Linux based one and programmed in Java.
In cases where the existing enterprise application is different, it becomes difficult to implement Hadoop because of the mismatch.
To solve this problem, a few companies came up with modified distribution models that suit the existing system in your organization.
Imagine changing a car’s factory fitted gasoline engine with a diesel engine because you have only diesel available in your locality (of course that doesn’t happen but this can give you an idea).
Let us look at a few such distribution flavors with one of their key features each. There can be a lot of description for each flavour, but this Hadoop tutorial will cover flavor features in short:
1. HortonWorks
It supports Microsoft Windows OS which makes it very popular
2. Cloudera
Cloudera supports the feature of managing multi-clusters
3. MapR
This is the only distribution that does not depend on Java with Pig, Hive, and Sqoop as it has its own MapRFS, a distributed file system like the HDFS.
4. IBM BigInsight
As the name suggests, it is able to provide deeper insights using advanced analytics.
A typical Hadoop tutorial for beginners won’t make you well versed with all the flavours, but the respective companies to provide training for people who are interested in their particular distribution.
Working
The working of Hadoop can be given in steps in the following manner, which also revises what we have already learned in this Hadoop tutorial earlier
(i) Submit data (e.g. a database of students appearing for a national exam).
(ii) Data gets broken down into blocks and HDFS stores metadata on NameNode and DataNodes.
(iii) MapReduce does the mapping and reducing, thus sorting the data.
(iv) Resource Manager breaks down the job into small tasks and hands over the tasks to Node Managers.
(v) Node managers finally do the work on all DataNodes.
Owing to some great features like being open source and compatible with commodity hardware, Hadoop is indeed a great choice and the name always pops up in every discussion related to big data or artificial intelligence.
Its dynamic parallelism and fault tolerance make it even more attractive.
It was many years ago that legendary American writer Arthur Conan Doyle observed, “It is a capital mistake to theorize before one has data.”
Today, the popularity of Hadoop proves him right, and we hope this big data Hadoop tutorial has convinced you too, and we suppose if someone asks you “What is Hadoop?”, you sure will be happily able to describe.
Data Science offers lucrative career opportunities. If you are also looking forward to building a career in Data Science, enroll in Data Science Master Course.







