
Support vector machines are a type of supervised machine algorithm for learning which is used for classification and regression tasks. Though they are used for both classification and regression, they are mainly used for classification challenges.
The original SVM algorithm was invented by Vladimir N. Vapnik and Alexey Ya. Chervonenkis in 1963.
A support vector algorithm is performed by plotting each acquired value of data as a point on an n-dimensional space or graph. Here “n” represents the total number of a feature of data that is present. The value of each data is represented as a particular coordinate on the graph.
After distribution of coordinate data, we can perform classification by finding the line or hyper-plane that distinctly divides and differentiates between the two classes of data.
Algorithm
Support vector machines are a tool which best serves the purpose of separating two classes. They are a kernel-based algorithm.
- A kernel refers to a function that transforms the input data into a high dimensional space where the question or problem can be solved.
- A kernel function can be either linear or non-linear. Kernel methods are a type of class of algorithms for pattern analysis.
- The primary function of the kernel is to get data as input and transform them into the required forms of output.
- In statistics, “kernel” is the mapping function that calculates and represents values of a 2-dimensional data in a 3-dimensional space format.
- A support vector machine uses a kernel trick which transforms the data to a higher dimension and then it tries to find an optimal hyperplane between the outputs possible.
- Kernel’s method of analysis of data in support vector machine algorithms using a linear classifier to solve non-linear problems is known as ‘kernel trick’.
- Kernels are used in statistics and math, but it is most widely and also most commonly used in support vector machines.
Application of Support Vector Machines

The use of support vector machine algorithms and its examples are used in many technologies which incorporate the use of segregation and distinction.
The real-life applications it range from image classification to face detection, recognition of handwriting and even to bioinformatics.
It allows the classification and categorization of both inductive and transductive models. The support vector machine algorithms make use of training data to segregate different types of documents and flies into different categories.
The segregation done by it is based on the data and score generated by the algorithm and then is compared and contrasted to the initial values provided.
It not only help and provide resourceful predictions but also reduce and remove the total and excess amount of redundant information respectively.
The results acquired by these machine algorithms are universal in nature and can be used to compare data obtained from other methods and approaches.
In a real-world application, understanding and finding the exact accurate class is quite difficult and is a highly time-consuming process.
This is due to the fact the data with the algorithm works with is in the millions. This overwhelming amount of data is what makes finding the perfect class a tedious task.
To help with that, its classifier has “tuning parameters”. These tuning parameters are ‘regularization parameter’ and ‘gamma’.
By adjusting and varying those two parameters, we can acquire higher levels of accuracy of a non-linear classification in shorter amounts of time.
By fine-tuning the above-mentioned parameters and a couple more, we can raise the accuracy level.
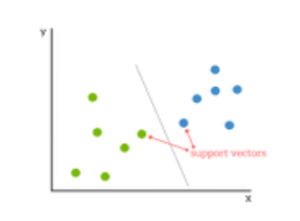
Tuning Parameters for Support Vector Machine Algorithm
1. Regularization
Often called as the C parameter in python’s sklearn library, the regularization parameter commands the support vector machine on the optimal amount of misclassification of each training data it wants to avoid.
Such support vector machine example is when larger numbers are used for the C parameter, the optimization will automatically choose a hyper-plane margin which is smaller if it successfully gets all the training data points correctly separated and classified.
Alternatively, for really small values, it will cause the algorithm to look for a larger margin to be separated by the hyper-plane, even if the hyper-plane might misclassify some data points.
2. Gamma
This tuning parameter re-iterates the length of influence on a single training data examples reach. The low values represent ‘far ’and the higher values of data are ‘close’ to the hyper-plane.
Points of data with low gamma which are far from the plausible hyper-plane separation line are taken into account in the calculation for the separation line.
On the other hand, high gamma refers to the points close to the assumed hyper-plane line and is also considered in the calculation of the hyper-plane separation line.
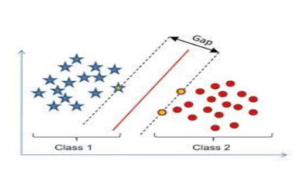
3. Margin
Last but not the least parameter is the margin. It also is an important parameter for tuning & is a vital characteristic of a support vector machine classifier.
The margin is the separation of the line which is closest to the class data points. It is important to have a good and proper margin in a support vector algorithm. When the separation of both the classes of data is larger, it is considered a good margin.
Having a proper margin ensures that the respective data points remain with their classes and so not crossover to some other class.
Also, characteristically, a good margin should have the class data points to be ideally at equal distance from the separation line at each side.
Use of Support Vector Machine Algorithm
It is the most primarily and also the most well-known classifier. It is one of the best-known machine algorithms for effectively classifying data points and helps in the easy creation and separation of classes.
They are beneficial when there are a larger number of variables. Such support vector machine example can be said for text classification from a bag of words model.
Non-linear kernels show promising and effective performance in most scenarios and often are head to head with other random forests.
Also, they are useful particularly when the need is t classify data by rank or commonly known as ordinal classification and are widely implemented in “learning to rank” algorithms.
Advantages of Support Vector Machines
1. Avoiding Over-Fitting
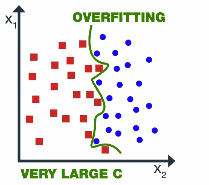
Once the hyperplane of the vector machine has been found, apart from the points closest to the plane( support vectors), most of the other data become redundant can be omitted.
This implies that small changes made cannot make any significant changes to the overall data and also leave the hyper-plane also unaffected. Thus the name ‘support vector machine’ means that such algorithms tend to generalize data efficiently.
2. Simplification of Calculation
They have comprehensive algorithms of regression which help in the classification of class data of two classes. This allows us to make our predictions and calculations simpler as the algorithm is presented in a graph image and can be used to estimate the class distinction.
Simpler visual calculation helps faster and more reliable data output rather than individually corresponding each support co-ordinate of the 2 cases.
Disadvantages of Support Vector Machines
The main disadvantages are primarily in the theory which actually only covers the determination of what the parameters will be a given set of values. Also. Kernel models can be sensitive to overfitting to the criteria of the model.
Moreover, the optimal choice of kernel often ends up to have all the data points as the supporting vector. This makes it more cumbersome to proceed with the algorithm.
Overview
Overall, its application is a highly lucrative option when it comes to the requirement of class separation. Having high efficiency and simplicity in its usage and prediction, it is a highly recommended option.
It can automatically handle and process any missing data value. However, the normalization must be taken care of and prepared manually.
It has a similar functioning capacity to a neural network and radial basis functions. Though, neither of these are considered as a viable approach to the regularization that is the basis of a support vector machine algorithm.
These algorithms can be modelled after complex actual real word problems like text and image separation and classification, handwriting recognition and even be models to bio sequence analysis.
When dealing with large numbers and amounts of data, a sampling of the data is often necessary. However, with support vector machine algorithms, such sampling is not required as this machine algorithm itself implements stratified sampling to reduce the amount of training data as per the requirement of the algorithm and precise computation.
Closing Thoughts
The method of being taken up as an alternative for conservative logistic regression has been observed and had its performance compared to real credit data sets.
Support vector machine algorithms prove to be a competitive avenue and have managed to add on to the cutting edge of the logistic regression model. It is an important concept from the educational and theoretical point of view.
To get the industry-relevant experience in support vector machines, join the advanced Data Science Using Python course and elevate your career in the Data Science Landscape.







