
Here, in this article, we will go through the basic introduction to Machine Learning which would further help us understand its importance on broader grounds.
In the digital age, we are exposed to the early stages of artificial intelligence on a daily basis. Spearheaded by Google, Machine Learning is being used by companies to predict user behavior and offer utility like never before. Entrepreneurs can take advantage of this burgeoning tech to build better businesses – but how far is too far?
Learning, like intelligence, covers such a broad range of processes that it is difficult to define precisely. A dictionary definition includes phrases such as “to gain knowledge, or understanding of, or skill in, by study, instruction, or experience,” and “modification of a behavioral tendency by experience.” Zoologists and psychologists study learning in animals and humans.
In this article, we focus on learning in machines. Machine Learning (ML) is coming into its own, with a growing recognition that ML can play a key role in a wide range of critical applications, such as data mining, natural language processing, image recognition, and expert systems.
ML provides potential solutions in all these domains and more and is set to be a pillar of our future civilization.Very broadly, that a machine learns whenever it changes its structure, program, or data (based on its inputs or in response to external information) in such a manner that its expected future performance improves. Here, we’ll learn step by step about the Machine Learning starting from the introduction to Machine Learning.
What is Machine Learning?
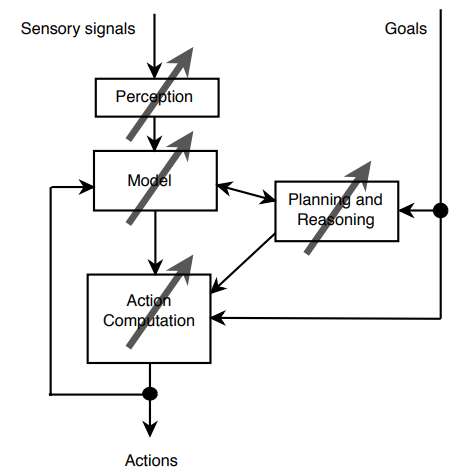
Machine Learning usually refers to the changes in systems that perform tasks associated with artificial intelligence (AI). Such tasks involve recognition, diagnosis, planning, robot control, prediction, etc. The “changes” might be either enhancement to already performing systems or ab initio synthesis of new systems. To be slightly more specific, we show the architecture of a typical artificial intelligence “agent” in below Figure.
This agent perceives and models its environment and computes appropriate actions, perhaps by anticipating their effects. Changes made to any of the components shown in the figure might count as learning. Different learning mechanisms might be employed depending on which subsystem is being changed.
Most readers will be familiar with the concept of web page ranking. That is the process of submitting a query to a search engine, which then finds web pages relevant to the query and which returns them in their order of relevance.
See e.g. Figure below for an example of the query results for “Machine Learning”. That is, the search engine returns a sorted list of web pages given a query. To achieve this goal, a search engine needs to ‘know’ which pages are relevant and which pages match the query.
Such knowledge can be gained from several sources: the link structure of web pages, their content, the frequency with which users will follow the suggested links in a query, or from examples of queries in combination with manually ranked web pages. Increasingly Machine Learning rather than guesswork and clever engineering is used to automate the process of designing a good search engine.
Introduction to Machine Learning: When Do We Need it?
When do we need Machine Learning rather than directly program our computers to carry out the task at hand? Two aspects of a given problem may call for the use of programs that learn and improve on the basis of their “experience”: the problem’s complexity and the need for adaptivity.
-
Tasks That Are Too Complex to Program
- Tasks Performed by Animals/Humans: There are numerous tasks that we human beings perform routinely, yet our introspection concerning how we do them is not sufficiently elaborate to extract a well-defined program. Examples of such tasks include driving, speech recognition, and image understanding. In all of these tasks, state of the art Machine Learning programs, programs that “learn from their experience,” achieve quite satisfactory results, once exposed to sufficiently many training examples.
- Tasks beyond Human Capabilities: Another wide family of tasks that benefit from Machine Learning techniques is related to the analysis of very large and complex data sets: astronomical data, turning medical archives into medical knowledge, weather prediction, analysis of genomic data, Web search engines, and electronic commerce. With more and more available digitally recorded data, it becomes obvious that there are treasures of meaningful information buried in data archives that are way too large and too complex for humans to make sense of. Learning to detect meaningful patterns in large and complex data sets is a promising domain in which the combination of programs that learn with the almost unlimited memory capacity and ever-increasing processing speed of computers opens up new horizons.
-
Adaptivity:
- One limiting feature of programmed tools is their rigidity once the program has been written down and installed, it stays unchanged. However, many tasks change over time or from one user to another. Machine Learning tools – programs whose behavior adapts to their input data – offer a solution to such issues; they are, by nature, adaptive to changes in the environment, they interact with. Typical successful applications of Machine Learning to such problems include programs that decode handwritten text, where a fixed program can adapt to variations between the handwriting of different users; spam detection programs, adapting automatically to changes in the nature of spam e-mails; and speech recognition programs.
Types of Machine Learning
The introduction to Machine Learning directs us to three types of Machine Learning Algorithms.
-
Supervised Learning
- A majority of practical Machine Learning uses supervised learning. In supervised learning, the system tries to learn from the previous examples that are given. (On the other hand, in unsupervised learning, the system attempts to find the patterns directly from the example given.) Speaking mathematically, supervised learning is where you have both input variables (x) and output variables(Y) and can use an algorithm to derive the mapping function from the input to the output. The mapping function is expressed as Y = f(X). Supervised learning problems can be further divided into two parts, namely classification, and regression.
- Classification: A classification problem is when the output variable is a category or a group, such as “black” or “white” or “spam” and “no-spam”.
- Regression: A regression problem is when the output variable is a real value, such as “Rupees” or “height.”
- Example: Based on past information about spams, filtering out a new incoming email into Inbox (normal) or Junk folder (Spam)
- A majority of practical Machine Learning uses supervised learning. In supervised learning, the system tries to learn from the previous examples that are given. (On the other hand, in unsupervised learning, the system attempts to find the patterns directly from the example given.) Speaking mathematically, supervised learning is where you have both input variables (x) and output variables(Y) and can use an algorithm to derive the mapping function from the input to the output. The mapping function is expressed as Y = f(X). Supervised learning problems can be further divided into two parts, namely classification, and regression.
-
Unsupervised Learning
- In unsupervised learning, the algorithms are left to themselves to discover interesting structures in the data. Mathematically, unsupervised learning is when you only have input data (X) and no corresponding output variables. This is called unsupervised learning because unlike supervised learning above, there are no given correct answers and the machine itself finds the answers. Unsupervised learning problems can be further divided into association and clustering problems.
- Association: An association rule learning problem is where you want to discover rules that describe large portions of your data, such as “people that buy X also tend to buy Y”.
- Clustering: A clustering problem is where you want to discover the inherent groupings in the data, such as grouping customers by purchasing behavior.
- Example: You have a bunch of photos of 6 people but without information who is on which one and want to divide this dataset into 6 piles, each with photos of one individual.
- In unsupervised learning, the algorithms are left to themselves to discover interesting structures in the data. Mathematically, unsupervised learning is when you only have input data (X) and no corresponding output variables. This is called unsupervised learning because unlike supervised learning above, there are no given correct answers and the machine itself finds the answers. Unsupervised learning problems can be further divided into association and clustering problems.
-
Reinforcement Learning
- A computer program will interact with a dynamic environment in which it must perform a particular goal (such as playing a game with an opponent or driving a car). The program is provided feedback in terms of rewards and punishments as it navigates its problem space. Using this algorithm, the machine is trained to make specific decisions. It works this way: the machine is exposed to an environment where it continuously trains itself using trial and error method.
- The algorithm is provided information about whether or not the answer is correct but not how to improve it. The reinforcement learner has to try out different strategies and see which works best. The algorithm searches over the state space of possible inputs and outputs in order to maximize a reward.
- Example: In manufacturing, the robot uses deep reinforcement learning to pick a device from one box and putting it in a container. Whether it succeeds or fails, it memorizes the object and gains knowledge and train’s itself to do this job with great speed and precision.
What Level of Maths Do We Need?
The foremost question when trying to understand a field such as Machine Learning is the amount of maths necessary and the complexity of maths required to understand these systems. The answer to this question is multidimensional and depends on the level and interest of the individual.
Here is the minimum level of mathematics that is needed for Machine Learning Engineers / Data Scientists.
- Linear Algebra: Matrix Operations, Projections, Factorisation, Symmetric Matrices, Orthogonalisation
- Probability Theory and Statistics Probability Rules & Axioms, Bayes’ Theorem, Random Variables, Variance and Expectation, Conditional Probability and Joint Distributions, Standard Distributions.
- Calculus: Differential and Integral Calculus, Partial Derivatives
- Algorithms and Complex Optimisations: Binary Trees, Hashing, Heap, Stack
Machine Learning approaches applied in systematic reviews of complex research fields such as quality improvement may assist in the title and abstract inclusion screening process. Through the article, I’ve covered the introduction to Machine Learning.
Machine Learning approaches are of particular interest considering steadily increasing search outputs and accessibility of the existing evidence is a particular challenge of the research field quality improvement.
If you are looking forward to building a career in Machine Learning, you should have a look at these Machine Learning Courses in Bangalore.
An increased reviewer agreement appeared to be associated with improved predictive performance. For a deeper analysis of Machine Learning basics, you should have a look at the Research Papers on Machine Learning.
If you are inspired by the opportunity provided by Machine Learning, enroll in Digital Vidya’s Machine Learning Course today.







