
Machine Learning interview questions is the essential part of Data Science interview and your path to becoming a Data Scientist. I’ve divided this guide to machine learning interview questions and answers into the categories so that you can more easily get to the information you need when it comes to machine learning questions.
Questions related to Theory/Algorithms
What is the difference between supervised and unsupervised machine learning?
Supervised learning requires training using labelled data. For example, in order to do classification, which is a supervised learning task, you’ll first need to label the data you’ll use to train the model to classify data into your labelled groups. Unsupervised learning, in divergence, does not require labeling data explicitly.
What’s the trade-off between bias and variance?
Bias is error due to over simplistic assumptions in the learning algorithm that you are using, which can lead to model under fitting your data and making it hard for model to give accurate predictions.
Variance, on the other hand, is error due to way too much complexity in your learning algorithm. Due to this complexity, the algorithm is highly sensitive to high degrees of variation, which can lead your model to over fit the data. In addition, you will be carrying too much noise from your training data for your model to be useful.
The bias-variance decomposition essentially decomposes the learning error from any algorithm by adding the bias, the variance and a bit of irreducible error due to noise in the underlying data-set. Essentially, if you make the model more complex and add more variables, you’ll lose bias but gain some variance — in order to get the optimally reduced amount of error, you’ll have to trade-off bias and variance. You don’t want either high bias or high variance in your model.
How KNN is different from k-means clustering?
The crucial difference between both is, K-Nearest Neighbor is a supervised classification algorithm, whereas k-means is an unsupervised clustering algorithm. While the procedure may seem similar at first, what it really means is that in order to K-Nearest Neighbors to work, you need labelled data which you want to classify an unlabeled point into. In k-means clustering it requires set of unlabeled points and a threshold only. The algorithm will take that unlabeled data and will learn how to cluster them into groups by computing the mean of the distance between different points.
What is Bayes’ Theorem? How it is useful?
Bayes’ Theorem gives you the posterior probability of an event given what is known as prior knowledge. Also, it is the basis behind Naive Bayes classifier. That’s something important to know when you’re faced with machine learning interview questions and answers. For detailed and simple explanation of Naïve Bayes visit here.

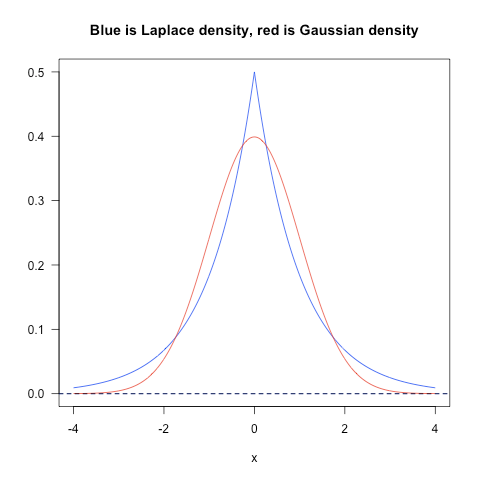
What is the difference between L1 and L2 regularization?
First, regularization is the technique which helps to solve over fitting problem in Machine Learning. L2 regularization incline to spread error among all the terms, while L1 is more binary, with most variables either being assigned a 1 or 0 in weighting. L1 corresponds to setting a Laplacean prior on the terms, while L2 corresponds to a Gaussian prior. I would say as a rule of thumb, one should always go with L2 in practice.
What is the difference between Type I and Type II error?
Don’t think this as something high-level stuff, interviewers ask questions in such terms just to know that you have all the bases and you are on the top.
Type I error is false positive, while Type II is false negative. This type error is claiming something has happened when it hasn’t. For instance, telling a man he is pregnant. On the other hand, Type II error means you claim nothing has happened but in fact something is. To exemplify, you tell a pregnant lady she isn’t carrying baby.
What is the difference between Probability and Likelihood?
Not going too deep in technical, Probability quantifies prediction of outcome, likelihood quantifies trust in model. For instance, someone challenges us to a ‘profitable gambling game’. Then, probabilities will serve us to compute things like the expected profile of your gains and losses. In contrast, likelihood will serve us to quantify whether we trust those probabilities in the first place; or whether we smell a rat.
What Deep Learning is exactly?
Most people don’t know this but Machine Learning and Deep Learning is not two different things, but Deep learning is a subset of Machine learning. It mostly deals with neural networks: how to use back propagation and other certain principles from neuroscience to more accurately model large sets of unlabeled data. In a nutshell, Deep Learning represents unsupervised learning algorithm that learns data representation mainly through neural networks. Explore a little about neural nets to answer deep learning interview questions effectively.
What’s the difference between a generative and discriminative model?
A discriminative model will learn the distinction between different categories of data, while A generative model will learn categories of data. Discriminative models will predominantly outperform generative models on classification tasks.
What is Time Series Analysis/Forecasting?
A Machine Learning data-set is a collection of observations. For example,
- Observation 1
- Observation 2
- Observation 3
But, a Time series data-set is different. Time series adds an explicit order dependence between observations: a time dimension. This additional dimension is both a constraint and a structure that provides a source of additional information.
- Time 1, Observation
- Time 2, Observation
- Time 3, Observation
How would you handle an imbalanced data-set?
Imbalanced data is, for example, you have 90% of the data in one class and 10% in other. This leads to problems such as, no predictive power on the other category of data. Here are few techniques to get over it,
- Obviously collect more data to balance
- Try different algorithm (Not going to work effectively)
- Correct the imbalance in data-set
Explain Pruning in Decision trees.
Pruning is you remove branches that have weak predictive power in order to reduce the complexity of the model and in addition increase the predictive accuracy of a decision tree model. There are several flavors which include, bottom-up and top-down pruning, with approaches such as reduced error pruning and cost complexity pruning.
In your opinion which one is more important: Model accuracy or Model Performance?
Questions like these tests your grasp over Machine Learning model performance and often look towards details. There are models with higher accuracy that can perform worse in predictive power, how does that make sense?
Well, it has everything to do with how model accuracy is only a subset of model performance, and at that, a sometimes misleading one. For example, if you wanted to detect fraud in a massive data-set with a sample of millions, a more accurate model would most likely predict no fraud at all if only a vast minority of cases were fraud. However, this would be useless for a predictive model — a model designed to find fraud that asserted there was no fraud at all! Questions like this help you demonstrate that you understand model accuracy isn’t the be-all and end-all of model performance.
What’s the F1 score?
It is a measure of the model’s performance. More technically, it is a weighted average of the precision and recall of the model, with results 1 being the best and 0 being the worst.
When should you use classification over regression?
Classification and Regression are both different in meaning. Classification produces discrete values while Regression gives you continuous results. You would use classification over regression, for example, when you wanted to know whether a name was male or female rather than just how correlated they were with male and female names.
What is convex hull?
Convex hull represents the outer boundaries of the two groups of data points. Once the convex hull is created, we get maximum margin hyperplane (MMH), which attempts to create the greatest separation between two groups, as a perpendicular bisector between two convex hulls.
General Questions
Do you have research experience in machine learning?
Machine Learning is emerging and no one wants novice players in their teams. Most employers hiring for Machine Learning position will look for your experience in the field. Research papers, co-authored or supervised by leaders in the field, can set you apart from the herd. Make sure you are ready with all the summary and justification of the work you have done in the past years.
What are the last Machine Learning papers you read? Why do you think that was important?
As this field is emerging day by day, it is crucial to keep up with the latest scientific literature to show that you are really into Machine Learning and not here just because it is the latest buzzword. Some good books to start with include Deep Learning by Ian Goodfellow.
How would you approach the “Netflix Prize” competition?
Netflix Prize was a famed competition where Netflix offered $1,000,000 for a better collaborative filtering algorithm. The team that won called BellKor had a 10% improvement and used an ensemble of different methods to win. Some familiarity with the case and its solution will help demonstrate you’ve paid attention to machine learning for a while.

What’s your favorite algorithm, and can you explain it to me in less than a minute?
This type of question mainly tests your ability of communicating complex and technical nuances with poise and the ability to summarize quickly and efficiently. Make sure you have a choice of algorithm which you can explain easily. Try to explain different algorithms so simply and effectively that a five-year-old could grasp the basics.
Where do you usually source data-sets?
This type of questions are the real tie-breakers. If someone is going for an interview, he/she must know the drill of some related question. It is questions like this which purely illustrates your interest in Machine Learning. See my post for detailed answer on where to find machine learning data-sets.
How do you think Google is training data for self-driving cars?
Questions like this check your understanding of current affairs in the industry and how things at certain level works. Google is currently using recaptcha to source labelled data on storefronts and traffic signs. They are also building on training data collected by Sebastian Thrun at GoogleX.
Industry Specific Questions
How would you implement a recommendation system for our company’s users?
There will be a lot of questions like this which will involve implementation of machine learning models to their company’s problems. You should definitely study company’s profile and its products before going in. In addition, factors such as, financials of the company, in which the company operates, what are their users will help you get a clearer picture.
How can we use your machine learning skills to generate revenue?
This is a tricky question, I would say. The ideal answer would demonstrate knowledge of what drives the business and how your skills could relate. To exemplify, if you were interviewing for Spotify, you could remark that your skills at developing a better recommendation model would remarkably increase user retention, which would then increase revenue in the long run. Or something like that.
Practical/Programming Questions
How will you handle missing data?
One can find missing data in a data-set and either drop those rows or columns, or decide to replace them with another value. In python library Pandas there are two useful functions which will be helpful, isnull() and dropna().
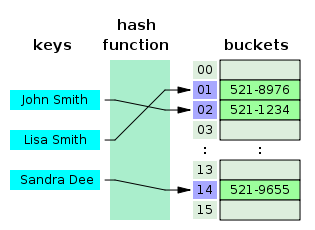
Describe a hash table.
A hash table is a data structure that produces an associative array. The key is mapped to certain values through the use of a hash function. They are often used for tasks such as database indexing.
Which data visualization libraries do you use and why they are useful?
What’s important here is to define your views on how to properly visualize data and your personal preferences when it comes to tools. Popular tools include R’s ggplot, Python’s seaborn and matplotlib, and tools such as Plot.ly and Tableau.
Do you have experience with Spark or big data tools for machine learning?
Spark is the big data tool most in demand now, able to handle immense data-sets with speed. Be honest if you don’t have experience with the tools demanded, but also take a look at job descriptions and see what tools pop up: you’ll want to invest in familiarizing yourself with them.
Considering the long list of machine learning algorithm, given a data set, how do you decide which one to use?
This is one more tricky question. Given what type of data there is, discrete, time series, continuous, you should give your answers.
Explain machine learning to me like a 5-year-old. (To check the ability of explaining complex concepts in simple terms)
There are a lot of definition of Machine Learning are out there, which one you think is the easiest and at the same time covers the entire meaning of Machine Learning? Tell us in the comments and let other readers give insights to how you think.
That’s all. I covered all the basic to intermediate interview questions so that you have a comprehensive list ready before your d-day!
If you wish to establish and/or accelerate your career in Machine Learning, then investing in a comprehensive Machine Learning Course, would be one of the best investments you could make.
Good Luck!







