
Do you want to rock your spark interview? Here is a list of top spark interview questions to help you.
The term big data is no longer a novelty. It has become a part of daily conversations. And, so has Hadoop. The Apache Hadoop and its distributed processing framework, MapReduce, has for long been known as the most trusted framework for large-scale data analysis.
However, there is a new player that has taken the industry by storm – Apache Spark. Spark interview questions have become commonplace in every big data job interview.
Spark was developed in 2009 and has achieved phenomenal growth in the past decade. Its future looks just as bright. Spark’s market is expected to witness a CAGR of 33.9% from 2018 to 2025.
You can leverage this growth to further your career by preparing yourself on Spark interview questions and answers. Ace the interview and land a job in the most exciting and fast-developing technology of recent times.
Top Spark Interview Questions
Q1. What is Spark?
Ans: Every interview will start with this basic Spark interview question. You need to answer this Apache Spark interview question as thoroughly as possible and demonstrate your keen understanding of the subject to be taken seriously for the rest of the interview.
Spark is a super-fast cluster computing technology. It is a distributed data processing engine that can be used to solve a variety of complex problems and perform highly complex computations.
Spark’s applications include SQL and ETL batch jobs across large datasets, machine learning tasks, processing the data streamed from sensors, IoT, financial systems, etc.
The development of Spark started in 2009, and it was adopted by the Apache Foundation in 2013. Spark quickly grew to become one of Apache’s top-level projects.
Today, it is backed by industry giants such as IBM, Databricks, and Huawei in addition to an enthusiastic community of individual developers.
Spark is based on Hadoop’s MapReduce. However, it offers significant improvements to MapReduce and overcomes the limitations of MapReduce.
a. Unlike MapReduce, Spark reduces the number of reading/write operations by caching the intermediate processing data. It doesn’t need to access the disk every time. Spark is, therefore, much faster than MapReduce.
b. Spark uses iterative algorithms to process distributed data in parallel.
c. The functional programming model of Spark is richer than that of MapReduce.
d. MapReduce runs heavyweight Java Virtual machine processes. On the other hand, Spark runs multi-threaded tasks inside the JVM processes. Due to this, Spark optimizes the CPU usage, starts faster, and is much better at parallelism.
Spark has a cluster management system of its own. Even though it is mostly used along with Hadoop, this is not a necessity. Hadoop is just one of the many ways to implement Spark.
When you answer the Spark interview question – what is Spark, make sure to mention this point. It shows that you have an in-depth understanding of Spark.
Q2. How to Learn Spark

Ans: Before you reach the interview, you need to learn Spark thoroughly and make sure you understand all the basic concepts. It is not enough to know what is Spark.
You need to know its components and have a working knowledge of using Spark. This the only way to answer all the Spark interview questions. Here are a few tips to get you started.
⇒ Even though Spark supports multiple languages such as Python, Scala, Java and R, there is a certain advantage to learning Spark using Scala. Spark is built using Scala. When you use Scala for Spark, you get access to many advanced features.
⇒ Spark is mostly implemented on Hadoop. Therefore, it makes sense to have a basic knowledge of Hadoop before starting to learn Spark.
⇒ You need to understand the Spark components and ecosystem.
⇒ You can join a Spark tutorial or course to get a clear picture of Spark and how it can be used.
⇒ To fully understand Spark and be able to answer all Apache Spark interview questions, you need to get hands-on experience in using it. Try to implement projects on Spark in your free time.
Q3. How Can Spark Help Your Career?
Ans: Why should I spend hours going over Spark interview questions and answers? Is Spark that important? Will I be asked Spark interview questions in all job interviews in the field of big data?
These are valid doubts that may arise in your mind. Let us deal with them first before moving on to the Apache Spark interview questions.

Spark may be new, but the rate at which companies are adopting it would make it seem like it has been around for a long time. Yahoo uses it for advanced analytics.
Clearstory uses to analyze data across multiple sources. E-commerce giants like Alibaba, Amazon, and eBay use Spark in their daily data processing and analysis. Many financial institutions are using it for real-time monitoring, analysis, and to power the retail banking and brokerage services.
Any organization that wants to work with big data uses Hadoop. However, Spark overcomes the limitations on the Hadoop MapReduce and offers faster computation without having to implement new clusters.
It comes as a boon for organizations. It has lead to increased adoption of Spark. Companies have moved on from asking “What is Spark?” to “Why aren’t we using Spark?.”
The increased Spark adoption has created a domino effect in the job market. There is a huge demand for Spark developers.
You can exploit this demand and catch a high-paying job. Apache Spark engineers and developers get an average salary of USD 105,000. An experienced Spark developer can easily command a figure upwards of USD 135,000.
It is not all about the money either. Spark is one of the latest technologies in big data and is witnessing some exciting developments. And, you get to be a part of this revolution.
How do you start on this journey? Well, first you need to take a course on Apache Spark and get some hands-on experience on Spark projects. Then you need to prepare yourself for the interview by going through various Spark interview questions.
Apache Spark Interview Questions and Answers for Freshers
For a fresher, a job interview is the first step towards getting that first paycheck. It may feel like your future rests on the interview.
However, there is no need to feel too pressured. Interviews are meant to assess your skill, not make you look bad. To give a stellar performance in your interview, start by making your resume look appealing and unique.
Make sure that you have the right skill set for the job.

In this case, make sure that you have course certificates from reputed institutions on Hadoop and Spark. Now, be prepared to face Hadoop and Spark interview questions.
Fresher interviews are mostly focussed on the basics. The interviewer wants to know if you have understood Spark and if you have the capability to work on a Spark project without being trained again its concepts.
All your Apache Spark interview questions for freshers will be in this direction. Here are some of the common ones.
Q4. What is Spark?
Ans: You can find the answer to this Spark interview question in the previous section.
Q5. What is RDD? What are the RDD operations in Spark?
Ans: RDD stands for Resilient Distribution Datasets. It is a distributed collection of objects. RDD is one of the fundamental data structures in Spark.
RDD dataset contains multiple partitions that can be computed on different nodes of the network, thereby allowing parallel processing.
A method applied to the RDD to finish a task is called an operation. There are two types of operations – transformations and actions. When a transformation is applied to an RDD, a new RDD has transformed data. The output of actions on RDDs is not-RDDs.
Q6. What are the different cluster managers in Spark?
Ans: There are three different cluster managers in Spark – YARN, Spache Mesos, and standalone deployments.
Q7. Explain lazy evaluations.
Ans: These are evaluations that are delayed until the point when you need to value. The execution does not start until an action is triggered.
When an operation is called on RDD, it is not executed right away. Instead, Sark keeps track of all the called operations using a DAG or Directed Acyclic Graph.
Q8. What is Shuffling?
Ans: Shuffling is the redistribution of data across partitions. Data transfer across stages happens during shuffling. It may lead to data movement across the Java Virtual Machines processes. Data redistribution between executors on separate machines is also called shuffling.
Q9. What does Spark UI Do? On which port is it available?
Ans: Spark UI displays information about the state of the clusters, jobs and the Spark environment. It is used for debugging and tuning. You can access it on port 4040 of the driver node.
Q10. How is Spark better than MapReduce?
Ans: The answer to this Spark interview question is already covered in the What is Spark section.
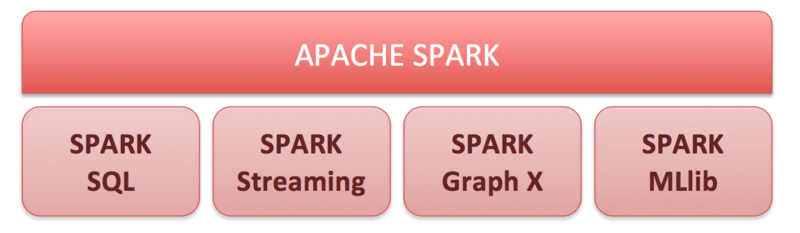
Q11. Name the components in the Spark ecosystem.
Ans: The components in the Spark ecosystem are:
⇒ Spark Streaming – It is responsible for processing the real-time streaming data.
⇒ GraphX – It implements graphs and parallel computations on the graphs.
⇒ Spark SQL – It is responsible for integrating Spark’s functional programming API with relational database processing.
⇒ MLib – This is the library used for machine learning.
⇒ Spark Core – It is a distributed execution engine that can perform large-scale parallel and distributed data processing.
Apache Spark Interview Questions and Answers for Experienced Professionals
Unlike the Spark interview questions for freshers, the ones for experienced professionals will dive into the details of the Spark implementation.
The interviewer will ask you Apache Spark interview questions that will require a bit more in-depth knowledge than the ones for freshers. Here are a few examples.
Q12. Explain the working of DAG in Spark.
Ans: Spark creates a DAG whenever an action is called. It is then submitted to the DAG scheduler. The schedule breaks down the operators into stages. Every stage contains tasks depending on the input data partitions. You can view the details of the RDDs that belong to a stage using the scheduler.
Q13. What are Partitions?
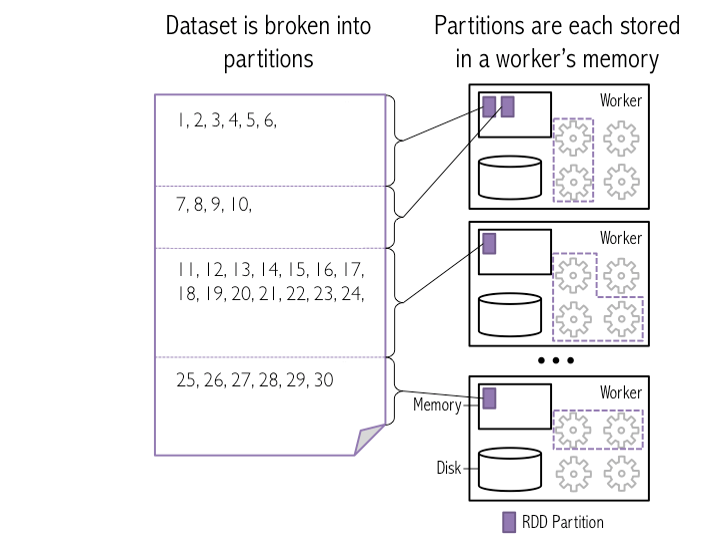
Ans: Spark breaks the data to allow parallel processing by the executors. These pieces are called partitions. It is essentially a collection of rows that sit in one physical machine in your cluster.
The partitions give you an idea about how the data is distributed across the cluster. The number of partitions depends and the number of executors determines the parallelism.
If you have only one executor, but multiple partitions, then parallelism is one. The same applies when you have a single partition.
Q14. How would you minimize data transfers in Spark?
Ans: Unnecessary and avoidable data transfers can slow down the system. To avoid this, you can
⇒ Use broadcast variable – It eliminates the need to ship copies of the variable for every task.
⇒ Use Accumulators – It parallelly updates the value of the variables during execution.
⇒ Avoid using operations such as repartitions, ByKey, etc. that trigger data transfers and shuffles.
Q15. How would you avoid serialization errors in Spark?
Ans: There are two ways to avoid serialization errors:
⇒ You can make the class/object serializable.
⇒ You can declare the instance within the lambda function.
Q16. Can you mention the most common mistakes made by developers while running Spark applications?
Ans: Spark is a distributed cluster network. Developers tend to forget this sometimes and run everything on the local node. Another common mistake is that they hit the web service several times using multiple clusters.
Q17. Explain the ML Pipeline.
Ans: The ML Pipeline is a simple way to view the ML tasks that are being executed. It consists of DataFrame, Transformer, and Estimator. The DataFrame holds different data types and is provided by the Spark SQL library. The Transformer converts one DataFrame into another. You can create a Transformer from a DataFrame using the Estimator.
Start Your Journey Towards a Successful Spark Career
By now, you should have a clear idea of the kind of Spark interview questions you can expect. In addition to these, you can expect questions on Hadoop and big data as well. Here is a video to help you with those questions.
Combine this with a certificate of course completion of the Data Science Course, and nothing can stop you from landing that dream job. The course will also cover other Hadoop tools to give you a well-rounded big data education. Since big data is one of the most desirable in the current job market, you will not regret your decision to enroll in the course.







