
In today’s day and age extracting data from the web is becoming more and more important. From getting valuable insights into creating useful metrics, a lot depends on our ability to extract useful data from the web. This article talks about how we can extract data via Web Scraping with Python.
Although there are several ways of extracting data from the web, there are two which have become most frequently used over time. The first and most desirable route is by using an API(Application Programming Interface). That’s because APIs allow us to access a lot of structured data directly from the provider.
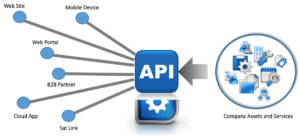
However, an API is not always a feasible option for data extraction for a couple of reasons. The first is that some providers may not want to provide access to structured data from their websites. The other is that the provider simply may not have the technical knowledge.
In such a case, web scraping with python becomes the only feasible option to extract data from the web. Although not the first choice, web scraping is nonetheless a very useful and effective technique of data extraction and is practically indispensable today.
An interesting fact about web scraping with python is that contrary to popular belief it is perfectly legal. The only exception to this is when a website has blocked crawlers via robots.txt or have a Terms Of Service page that indicates that they don’t allow web scraping shouldn’t be crawled.
What is Web Scraping?
Web scraping is a computer software technique of extracting data from the web. Web scraping allows you to convert unstructured data on the web (present in HTML format) into structured data (such as a database or spreadsheet).
Moreover, effective web scraping services can extract data from a number of unstructured formats from HTML and other websites to social media sites, pdf, local listing, e-commerce portals, blogs, and many other online resources.
What are the situations in which Web Scraping is required?
As discussed, web scraping is the best and sometimes only solution to extract large amounts of data from the web when APIs are not available. Although web scraping has been around for a while, it has never been as reliable as it is today.
In today’s day and age, analysis of key trends is the best way to make sound business decisions. In fact, with a deluge of information out there on the internet, it simply doesn’t make business sense to make important decisions without proper analysis. Web scraping gives you al the raw data you need to run the right analytics that will give you in-depth business intelligence.
Another important use of web scraping is in monitoring your brand. In today’s age of instant feedback, negative mentions on social media and other websites, be it Facebook or Twitter or Google Business can ruin your online reputation.
This can have a serious impact on revenues in the long-term. Effective web scraping techniques can help you keep an eye on all your mentions on the web, helping you manage your brand more effectively.
Other applications of web scraping include finding listings for a real website, powering Artificial Intelligence experiments which require many keyword-linked images, monitoring prices of competitors on different e-commerce websites and tracking the stock market real-time.
Why is Python a suitable language to use for Web Scraping?
First, python programming language is an easy language to learn and work with because the syntax reads like simple English and the core concepts are easy to understand. So if someone wants to scrape the web in an efficient manner but has no previous programming language, Python is the best choice.
The other advantage of Python is that it has the most elaborate and supportive ecosystem when it comes to web scraping. While many languages have libraries to help with web scraping, Python’s libraries have the most advanced tools and features.
Python is also an interpreted scripting language, which makes it compile free. What this means is that changes are implemented immediately when you run the application you’ve written the next time. Thus you’re able to fix mistakes and iterate quicker when web scraping with Python.
Which libraries can be used for Web Scraping with Python?
When you are web scraping with Python, you have access to some of the most advanced and supportive web scraping libraries.
(i) Scrapy
Scrapy is a comprehensive framework written for web scraping in Python. It allows you to do a number of things, from downloading the HTML of websites to storing them in the form you want to. While it is definitely very efficient and has a lower CPU usage, it is hard to install and maybe too much for simple scraping tasks.
(ii) Urllib
Urllib can be used for fetching URLs. It defines the functions and classes that help with URL actions (basic and digest authentication, cookies, redirections, and so on).
(iii) BeautifulSoup (BS4)
BeautifulSoup is a parser that allows you to pull out information from the webpage. You can use it to extract lists, tables, paragraphs. You can even use filters to extract information from different web pages. It is one of the easiest and most popular tools to use.
(iv) LXML
LXML is a high performing parsing library that parses HTML and XML pages. While it is one of the best quality parsers out there, its complex documentation makes it a difficult tool to use for beginners.
Other important libraries for web scraping in Python include Mechanize, Scrapemark, Selenium and Requests. In this guide, we will be using a combination of Urllib and BeautifulSoup to scrape the web. Since BeautifulSoup can only parse the data and not fetch the web pages, Urllib needs to be used in addition to BeautifulSoup.
HTML tags you need to know for Web Scraping with Python
While web scraping with python doesn’t require you to be an HTML expert, it does use HTML tags which you need to become familiar with before getting started. Here’s what basic HTML syntax looks like.

Here’s a guide to these basic HTML tags.
- <!DOCTYPE html> : All HTML documents start with this declaration to identify it as an HTML document
- The HTML document is contained between <html> and </html>
- The part of the HTML document which is visible is between <body> and </body>
- HTML headings are defined with the <h1> to <h6> tags, in decreasing order of size
- HTML paragraphs are indicated through the <p> tag
Some other HTML tags that would be useful to know for web scraping with Python are given below.
- The <a> tag is used for links. For instance, “<a href=“http://www.google.com”>This is a link for google.com</a>”
- HTML list starts with <ul> (unordered) and <ol> (ordered). Ordered lists are numbered or alphabetical lists while unordered lists refer to bulleted lists.
- HTML tables are defined using<Table>, row using <tr> and rows are further divided into data using <td>
Steps to scrape the web using Beautifulsoup
The steps below will take you through the journey of scraping this Wikipedia page using BeautifulSoup. The goal is to extract the list of state and union territory capitals in India as well as details like the date of the establishment, and the former capital and others from the Wikipedia page.
Import necessary libraries:
1. Import the library Urllib2 which will be used to query the website
import urllib2
2. Specify the URL that is to be queried
wiki = “https://en.wikipedia.org/wiki/List_of_state_and_union_territory_capitals_in_India”
3.Query the website and return the HTML to the variable ‘page’
page = urllib2.urlopen(wiki)
4. Import the Beautiful soup functions so that you can parse the data which has been returned by the website
from bs4 import BeautifulSoup
5. Parse the HTML in the ‘page’ variable, and store it in the Beautiful Soup format
soup = BeautifulSoup(page)
Use the “prettify” function to get the structure of the HTML page
This will help you see the structure of different HTML tags and you can play around with these to extract data.
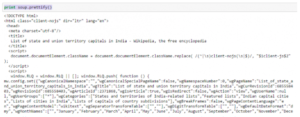
Work with HTML tags
- soup.<tag>: Return content between the opening and the closing tag including the tag.
In[30]:soup.title
Out[30]:<title>List of state and union territory capitals in India – Wikipedia, the free encyclopedia</title>
- soup.<tag>.string: Return string within a given tag
In [38]:soup.title.string
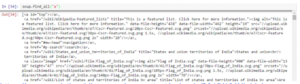
Out[38]:u’List of state and union territory capitals in India – Wikipedia, the free encyclopedia’ - Find all the links within the page’s <a> tags: As discussed, we can tag a link using the tag “<a>”. So, you can go with soup.a and it will return all the links available on the web page.
In [40]:soup.a
Out[40]:<a id=”top”></a>
This gives us only one output. In order to extract all the links that are present within <a>, the “find_all()” needs to be used. This can be seen in the image below.
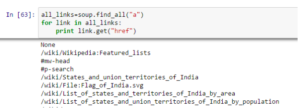
This gives us not just the links but also the titles and other information. To return only the link we need to use the “href” attribute as shown below.
Identify the right table
We need to find the right table since we are specifically looking to extract data about state capitals. We start by using the command below to extract data from all the table tags.
all_tables=soup.find_all(‘table’)
After this, we need to identify the table we need. We use the attribute “class” to find the right table. You can use the command shown below for this.
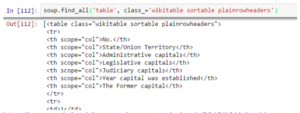
Extract the information to the DataFrame
For this, you will need to iterate through each row (HTML tag (tr)) and then assign each element of tr (HTML tag (td)) to a variable and append it to a list. To do this we need to look at the HTML structure of the table.
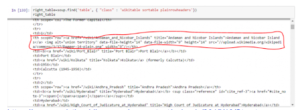
As you can see in the image above, the second element of <tr> is within tag <th> instead of the more commonly used <td>. We need to account for this.

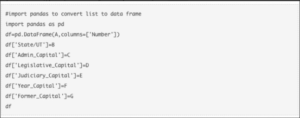
In order to access the value of each element, you need to use the “find(text=True)” option with each element. This is what the code looks like.
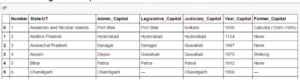
You will now get the output in the format below.
You can also see another great example of web scraping with Python using BeautifulSoup and Requests in this video.
Just like the examples here, many different kinds of websites can be scraped with Python using BeautifulSoup and other libraries. Given its wide-ranging applications and relative simplicity, web scraping with Python is definitely a great tool to have in one’s skill set.
Join the Python Programming Course and start your career as a Data Scientist.







