
Representation learning, a part of decision tree representation in machine learning, is also known as feature learning. It comprises of a set of techniques that helps the system discover representations required to detect the features or to classify the raw data available.
This learning is an important part of decision tree representation in machine learning as it replaces manual intervention to a large extent and allows the machine not only to learn the features but also to apply them to specific tasks.
For large scale data and applications, representation learning is very helpful in facilitating classification and representation of data.
According to Data Science Central, by 2020, there will be more than 50 billion smart connected devices in the world, collecting, analysing and sharing data.
This proves that data science has emerged at a fast pace and gained immense popularity.
Types of Representation Learning
Supervised and Unsupervised
1. Supervised
When the features are learned using labeled data. Input is labelled with the desired output value, and hence it is easier for the system to give the output once the input is fed. The following methods are examples of supervised learning:
- Dictionary learning –When each data point is represented as a weighted sum of the elements which means that input is fed when the output is already defined.
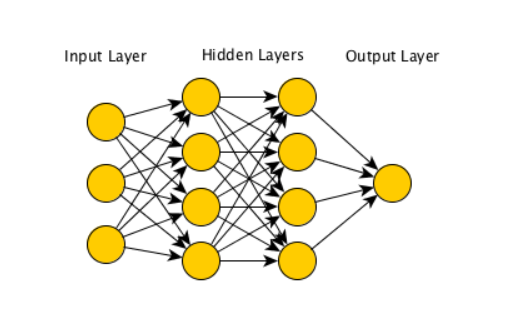
- Neural Networks – These are algorithms that try to mimic the brain, the network of neurons synthesizes information primarily in 3 stages:
- Input
- Hidden layer(not capable of recognizing the value)
- Output
2. Unsupervised
When the features are learned using unlabeled data. When the learning is performed in an unsupervised way, features are learned from an unlabeled dataset and it is then used for improving performance in a supervised setting.
The following are examples of unsupervised learning:
- K means clustering – It is used for vector classification. In a given set of vectors, k means clustering method groups these into k clusters in a way that each subset is classified in a cluster which has the closest mean.
- Principle component analysis –this method is often used for dimension reduction.
- Local Linear embedding – this method uses high dimension input to generate low dimension output.
- Unsupervised dictionary learning – it doesn’t use labeled data and rather uses the structure underlying the input data to produce optimized elements for the dictionary. Sparse Matrix learning is a relevant method under this.
Sparse Learning Representation
Sparse learning is when objects which are rich in information are constructed using sample given objects. It is also known as a sparse approximation and is used for linear equations. It is mostly used for image processing, signal processing, imaging techniques etc.
In equations which have 2D, simply with x row and y column, having values of x*y. Sparse representation has become a common tool as compared to other methods.
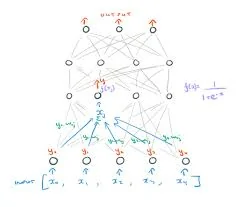
Learning Representations by Back-Propagating Errors
It is one of the algorithms which help in building and training neural networks with hidden layers. Neural networks with more than one hidden layer are referred to as deep neural networks and back-propagating error is used to train such deep neuron networks.
The basic idea is to adjust the weights of the connection in the network to minimize the difference between the actual and desired output. As the weights are adjusted, the hidden internal objects represent the features of the tasks.
The concept of back-propagating errors is that the errors are identified at the output, and they are distributed backward in the layers of the networks. The term was derived by multiple researchers in the early 60s and was implemented on computers.
Here are some advantages and disadvantages of back-propagating errors representation:
Advantages:
- These are very accurate as the errors which are identified at the outcome and are distributed back in the hidden layers.
- These are cheaper methods over any other method of analysis
Disadvantages:
- It is a time taking method as we let the entire process work first and then move back after identifying the errors, usually which is very time-consuming as compared to other methods.
Decision Tree Representation
Decision Tree Representation is the most powerful method for classification and regression in representation learning. These are structures made like trees through which visual and explicit representation of decisions and decision making is shown.
Decision trees are drawn upside down or otherwise, left to right or right to left, in which nodes represent test on attribute and branches key outcome and leaf node denotes class label.
The three nodes in a decision tree diagram are represented as follows:
- Decision nodes – squares
- Chance nodes – circles
- End nodes – triangles
Classification trees are used in classifying decisions like dead or live, open or close, profit or loss, etc. while Regression trees are used to predict continuous values.
A Decision tree is used in operations research and operations management.
Here are a few advantages and disadvantages of decision tree representation:
Advantages:
- Very easy and clear, can be interpreted fast and easily if you are clear with the rules.
- Can be used to analyze complex data
- Can be used with other techniques and tools
Disadvantages:
- A small change in data can lead to change in the entire structure of the tree as they are interconnected.
- Not the best method to use when it comes to 100% accuracy. There are much better tools available to ensure that.
- Representation of calculation can get complex especially when the outcomes are linked together.
The success of decision tree representation in machine learning is directly proportional to the features used in it. Machine learning used a large amount of manual intervention in creating features which are knowledge-based after researching and repeated trial and errors.
The researchers took several years to understand that learning can be automated using raw data and that is how it came into the picture.
Representation learning algorithms helped in automating the analysis of large, vast amounts of heterogeneous data, learning representations by back-propagating errors and learning a sparse representation for object detection.
Representation data uses objects of varied colors, sizes, features and shapes to represent values. It uses both similarities and differences in datasets to draw out patterns on its own and automate data analysis.
In representation learning, things are represented using vectors and functions. They are also used as deep learning algorithms where multiples levels are represented increasing the complexity.
Goals and Principles of Representation Learning

There are three levels of analysis:
- Computational
- Algorithm
- Implementation
It has gained popularity over the years and has become one of the significant tools in machine learning for decades now, but its importance has gained primarily because of deep learning.
Traditional methods involved dealing with datasets. However, deep learning involves objects, images, sounds which are the modalities of a data set. Here is what deep learning exactly means.
Deep Learning Algorithms
Deep learning algorithms are a subset of machine learning to learn multiple complex levels of representations increasing complexity and abstraction. It is the concept of learning by example for computers; computers can achieve excellent accuracy much beyond human capabilities using this concept. This made learning a sparse representation for object detection and learning representations by back-propagating errors easy.
Deep learning only uses labeled data and high computing power. It is a big leap for machine learning. Few examples of deep learning are self-driving cars, aerospace and defense, medical research, electronics, etc.
Why Deep Learning Matters?
Deep learning matters because it is the most effective way of data representation and because of the abundance of available data, it is used in all fields, google maps, facebook, translations and more.
The modalities it uses are fed into the system forever, and the information is mapped to the modality resulting in accuracy and clarity of output.
Though deep learning has significantly contributed to artificial intelligence to accomplish a lot, there is a lot more yet to be explored.
Autoencoders
An auto-encoder is a kind of artificial neural network; it is used for encoding and decoding a set of data in unsupervised learning. It is used in the reduction of dimensions. It consists of encoder and decoder for deep learning.
The encoder uses raw data as input and representation as output while the decoder uses the output as input and produces raw data as output. Auto-encoders applies backpropagation in a way that output becomes the input in the next set.
The input is compressed in the latent space representation, and the output is then reconstructed from the representation. The best part of autoencoders is that they preserve a lot of information in them. There are four types of autoencoders:
- Vanilla autoencoder
- Multilayer autoencoder
- Convolutional autoencoder
- Regularised autoencoder
Encoder and decoders are constructed using a restricted Boltzmann machine called RBM. RBM can be used in unsupervised learning. Each edge of RBM has a weight which represents the energy function. These are useful components of machine learning.
Representation Learning in a nutshell!
Self-programming and self-automation is the gist of machine learning and representation, and deep learning is ways to do it. Representation of information in ML is a critical stage towards the entire process as output will only make sense if represented in the best way.
With representation, come two more stages which are evaluation and optimization. While representing a model would mean how it would look like, evaluation teaches us to distinguish good from bad and optimization is when we can find the best ones among the lot.
We should be careful while representing the data, visualizing by plotting the apt graphs, debugging the data and monitoring by featuring quantiles and examples over time.
Closing Thoughts
Representation of words as vectors must be used in representation learning as it is critical in representing the data.
As a matter of fact, it makes learning a sparse representation for object detection easy and helps in learning representations by back-propagating errors.
Join the Machine Learning using Python to specialize in Machine Learning & Python and create a strong foundation for your career.


















This article is quite insightful.