
We cannot start discussing Semi-supervised learning without discussing Artificial Intelligence first, probably the most popular buzzword of this century.
Usually, people not related to the field imagine robots taking over civilizations and taming humans. However, AI is far different, or at least, much more than just that possibility.
It opens the doors to a virtually uncountable number of benefits. AI promises to make almost every daily task easier, faster, and more efficient by making computers ‘intelligent’.
According to research by Markets and Markets, the AI market will cross $190 billion by 2025 (which was $16 billion in 2017).
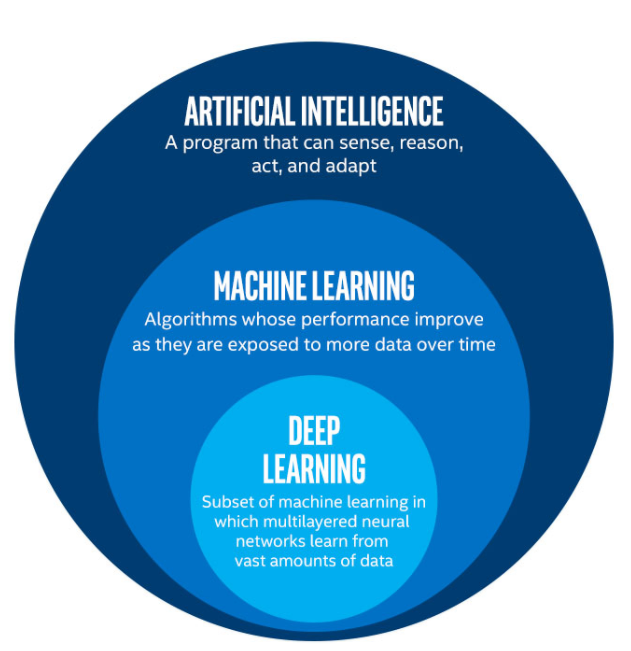
For machines to become intelligent, they should be able to teach themselves, hence the term ‘Machine Learning’.
Unlike humans, machines cannot find anything to learn by themselves and we have to provide them with data from which we want them to learn.
The kind of data provided to them determines whether the learning is supervised, unsupervised, or semi-supervised.
So what is semi-supervised learning really? Let us find out.
Types of Machine Learning
As mentioned before, the ability of machines to learn from data is called machine learning.
The world today is filled with tremendous amounts of data, from data about who buys how many soft drinks to how many people visit which websites and from political inclinations to data about absolutely anything.
If not all, much of this data holds significant value.
This data can be used to design marketing campaigns, to diagnose diseases better, to personalize everything from entertainment to shopping carts, and much more.
That is possible only when machines themselves learn from this data. To this end, data should be fed to computers initially, which brings us to three types of Machine Learning.
Before touching on the topic of what semi-supervised learning is, let us have a look at its different types.
1. Supervised Learning
As the name suggests, the learning of the computer is supervised. Not in a sense of sitting there and monitoring the learning, but by feeding data that is completely labelled.
Let us take a relatively simple example. We can call it supervised learning if we feed training data to the computer that includes images of spoons and forks with respective names labelled to it.
Thus, after learning from a number of labelled images, if the system is now shown a new image of a spoon, it will recognize and label it as a spoon, even if the exact image wasn’t a part of the training data.
Supervised learning is the most accurate machine learning method. You can learn more about it from this comprehensive guide on supervised learning.
2. Unsupervised Learning
Having labelled data may seem simple, but in the real world, the data is often a very large and complex set of unlabeled items.
The machines can still try to recognize patterns and teach themselves. It may not necessarily label common names of spoon and fork, but it will learn nevertheless.
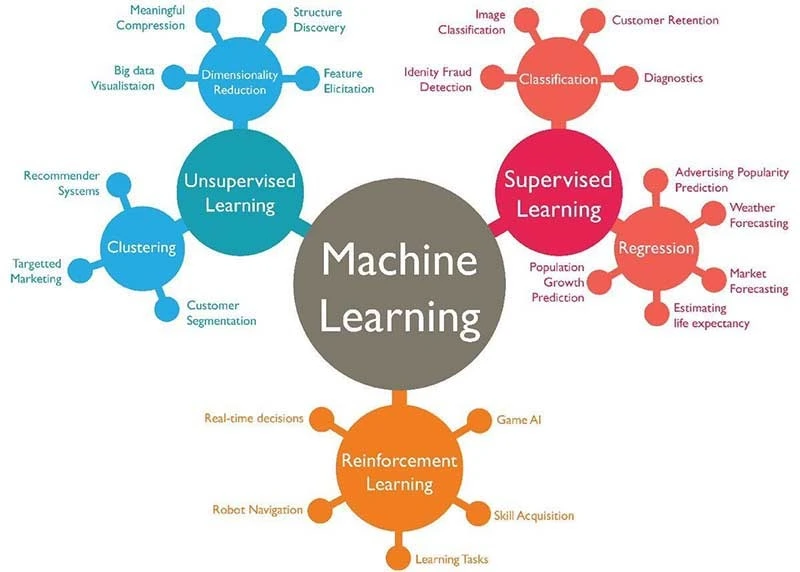
3. Semi-Supervised Learning
Semi-supervised learning is a combination of the above two. It includes a partially labelled training data, usually a small portion of labelled and a larger portion of unlabelled data.
Let us go ahead and understand the ways in which semi-supervised learning tackles the challenges of both supervised and unsupervised learning.
Understanding Semi-Supervised Learning
In a way, semi-supervised learning can be found in humans as well. A large part of human learning is semi-supervised.
For example, a small amount of labelling of objects during childhood leads to identifying a number of similar (not same) objects throughout their lifetime.
Suppose a child comes across fifty different cars but its elders have only pointed to four and identified them as a car.
The child can still automatically label most of the remaining 96 objects as a ‘car’ with considerable accuracy.
Why Semi-Supervised Learning?
Having large amounts of unlabelled data often pose the problem of misidentification or lack of accuracy.
An ideal solution would always be to have a large and labelled set of data, but that requires spending a lot of time and other resources, as the data may include thousands and even millions of values.
Semi-supervised learning seeks to strike a balance between both the other types by eliminating the need to tediously and expensively label large data as well as improves accuracy and learning.
This is usually done by including a small portion of labelled data in a large unlabeled set.
The machine can now use the small labelled set to learn the output values to given inputs and hence identify/categorize/predict outputs or values of unlabeled data with better accuracy.
To answer ‘what is semi-supervised learning’ briefly, it can be said that it is the best of both worlds as far as the learning methods are concerned. Here is a video that explains what SSL is and what makes it attractive.
Characteristics of a Typical Semi-Supervised Learning Dataset
A classic semi-supervised learning example would have a relatively tiny labelled data set, such as less than a fourth or fifth of the total data.
For a data scientist, however, it is important to identify the learning method by looking at the training data. Following are a few characteristics that make certain data suitable for semi-supervised machine learning:
1. Size of unlabeled portion
Typically, SSL is used only when a small percentage of the data values are labelled. If the labelled data is larger, then it is instead more preferable to go for supervised learning.
2. Input-Output Proximity
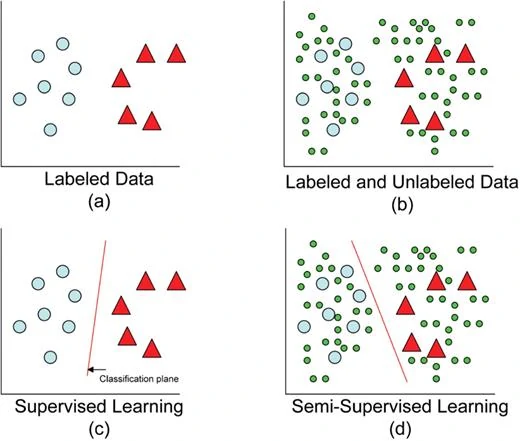
In semi-supervised learning, for an unlabelled input, the system tries to give an output based on a labelled data point in its proximity.
SSL works on the idea that two data points belonging to the same cluster will mostly be in close proximity of each other.
If the labelled data portion consists of data points under the same classification but is separated by a low-density area, it may affect the learning accuracy.
Take a look at the following image that depicts a semi-supervised learning example.
In the last picture, the system has distinguished labelled items perfectly but the unlabelled data points are classified as per their proximity to one of the labelled data points.
3. Simplicity/Complexity of Labeling
An interesting aspect of semi-supervised learning is that if the inference of labelled data is complex, it becomes a larger problem than the original problem.
In addition, having too many attributes of labelling in the labelled set also increasing complexity and affects accuracy.
4. Inductive and Transductive Learning
When having a mix of labelled and unlabelled values, there can be two kinds of approaches in learning. The first is simple to understand the method of ‘induction’.
Inductive inference studies the labelled data and creates reasoning that builds a general rule for classification. It then tries to include the test cases under these general classifications.
Transduction does not prefer generalization very much. The transductive inference draws reasoning from specific training cases (as against creating general rules) and applies this reasoning to specific test cases.
The inventor of Support Vector Machine (SVM) method and statistical learning expert Vladimir Vapnik has been known to support the transductive method by saying “Try to get the answer you really need, instead of a general one.”
Assumptions Used
Certain assumptions are necessary for the structure of the data provided while using semi-supervised learning. Following are some of the assumptions that can be made:
1. Continuity Assumption
It is always more likely for points closer to each other to share the same label (check image under ‘input-output proximity’ and observe closeness of similar shapes). Although there may occur some exceptions to this assumption, it simplifies the decision boundaries.
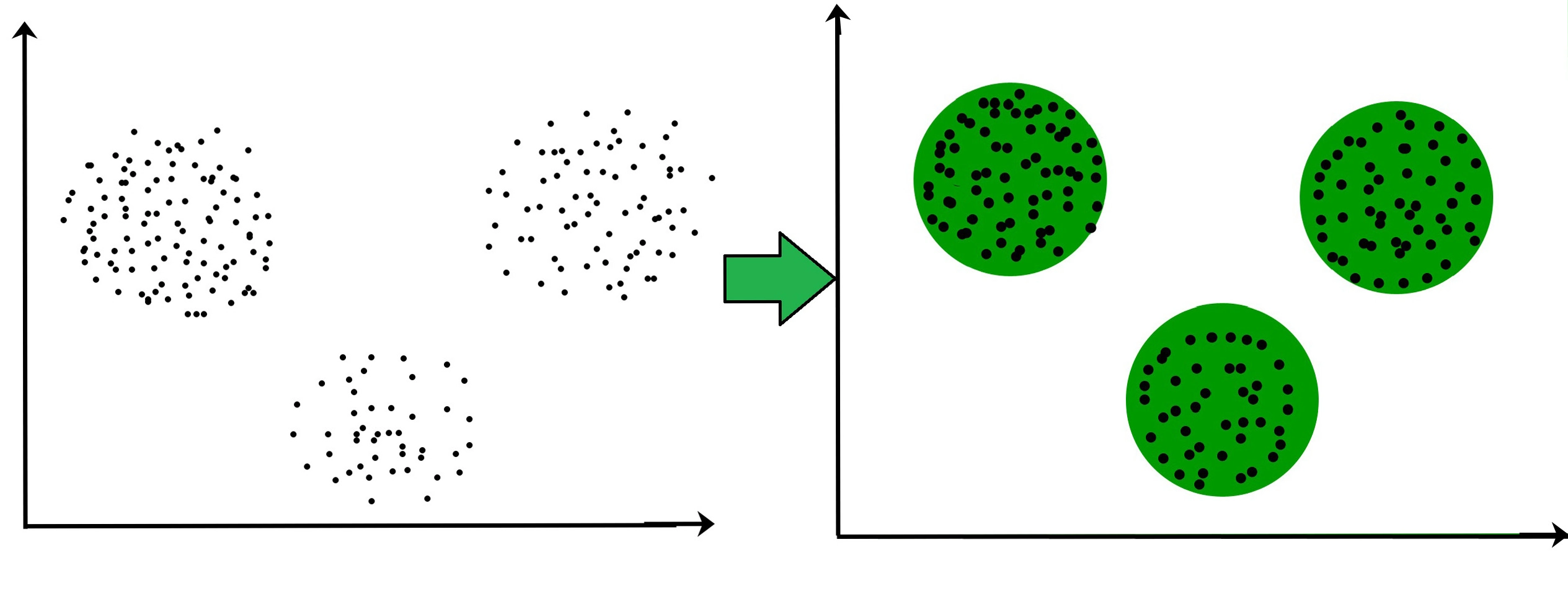
2. Cluster Assumption
The data points are assumed to form discrete clusters with each cluster having all examples of the same label.
3. Manifold Assumption
In cases where the data may lie in higher dimensions and it becomes extremely difficult to map the data in those dimensions, manifold assumptions can be used.
It assumes that the data lies on much lower dimensions and by learning those lower dimensions, embedding that data becomes much easier.
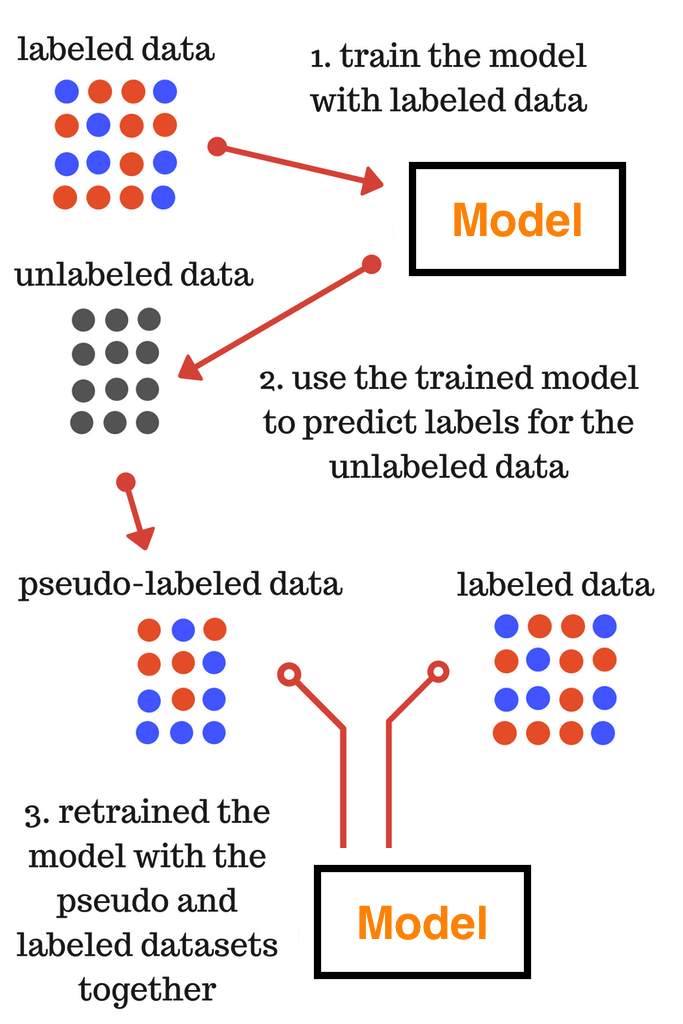
Pseudo Labelling
Pseudo labelling is a simple method that consists of the following steps:
(i) We first use a reliable training set that gives us good results to train the system.
(ii) We then feed the system with the unlabelled test set to produce outputs. These outputs may or may not be accurate, and are also called pseudo labels.
(iii) We combine the labelled training data from step 1 and test data from step 2.
(iv) The model is trained again using the above-mentioned concatenated data.
Following image represents nicely the semi-supervised learning example using pseudo labelling.
Semi-Supervised Learning Algorithms
1. Self Training
It is the simplest SSL method which relies on the assumption that one’s own high confidence predictions are correct.
It is a wrapper method and applies to exist complex classifiers. However, early mistakes may be reinforced into learning.
2. Generative
Generative models process the data to make deductions about the data into its digital essence. As opposed to discriminative modelling, generative produces something, here, prediction and creation of new data points based on existing data.
3. Low-Density Separation
Low-density separation works on the simple logic of placing boundaries where there are fewer data points.
Some other semi-supervised learning algorithms include heuristic methods, graph-based separation, SVM, etc.
4. Practical Applications
All the discussion about the SSL approaches and benefits and semi-supervised learning algorithms is fine, but first, let us see what is semi-supervised learning in terms of everyday applications.
(i) Web page classification
(ii) Detection of fraudulent activities
(iii) Facial recognition
(iv) Speech recognition
(v) Genetic sequencing
Wrapping Up
There is no doubt about the potential and rise of machine learning, and semi-supervised learning often seems to strike a balance between the accuracy of supervised and costs or unsupervised learning methods.
With careful inclusion of labelled data set, semi-supervised learning can perform wonders.
It won’t be a surprise to come across a semi-supervised learning example frequently in the data science world.
If you are looking at machine learning as the next step in your career, it is a great thought and here is a list of machine learning interview questions that will certainly be of great help.
If you are also looking forward to building a career in Data Science, enrol in the Data Science Master Course.

















